Aspetti organizzativi e qualità dei dati¶
Aspetti organizzativi¶
Nota
AZIONE 6: INDIVIDUA UNA DATA GOVERNANCE E ASSICURATI CHE I PROCESSI INTEGRINO IL RILASCIO DI DATI APERTI E IL COINVOLGIMENTO DEGLI UTENTI …
Si adotta il modello operativo mostrato in Figura 5. Il modello ha l’obiettivo di garantire la produzione e la pubblicazione di dati (aperti) di qualità attraverso un processo omogeneo, auto-sostenibile, coordinato tra gli organi interni dell’amministrazione, con la definizione di procedimenti condivisi che possano creare un tessuto sufficientemente robusto e stabile nei suoi punti fondamentali, e necessariamente elastico per l’applicazione alle diverse realtà amministrative.
Per attuare il modello è necessario (i) definire una chiara data governance interna con l’individuazione di ruoli e relative responsabilità; (ii) integrare le sue fasi sia verticalmente, rispetto ai processi interni già consolidati, che orizzontalmente rispetto alle necessità delle diverse amministrazioni. L’applicazione del modello deve avvenire in maniera costante: le attività non si esauriscono con la mera pubblicazione dei dati, ove questo sia possibile, ma devono prevedere un costante aggiornamento, monitoraggio e coinvolgimento con gli utenti finali.
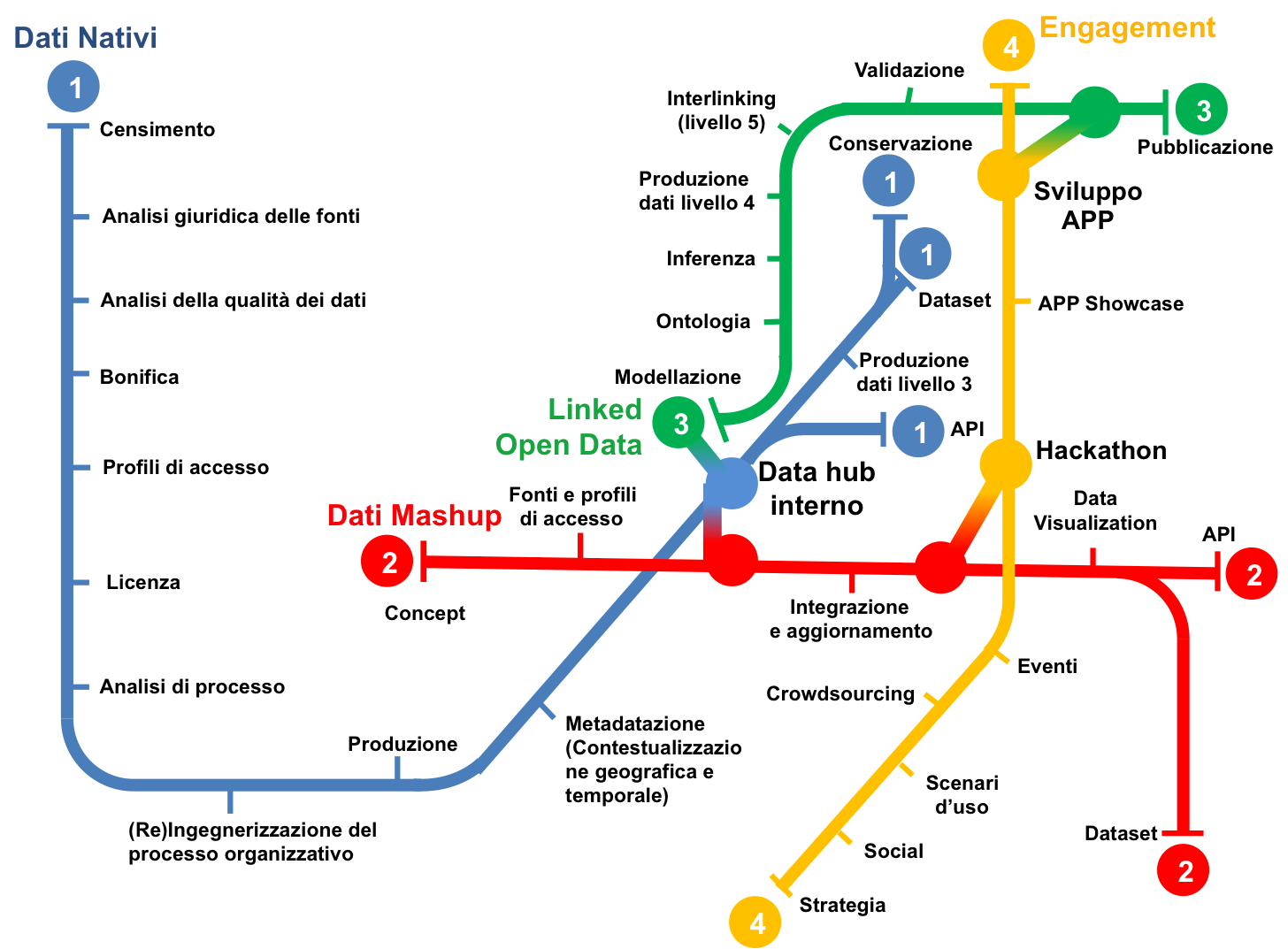
Fig. 5 Figura 5: Modello operativo: produzione e pubblicazione di dati aperti
L’attuale contesto, sempre più incentrato sull’uso dei dati, pone il problema di intervenire su alcune fasi della catena del valore del dato: la scelta della migliore fonte informativa, il controllo della qualità del dato, l’integrazione di fonti diverse, la tempestività nell’aggiornamento, ecc.
Avvertimento
Al riguardo, oggi si rende sempre più necessaria la revisione dei processi e dei modelli dei sistemi informativi delle pubbliche amministrazioni, organizzandoli in maniera organica, facendo in modo che il processo di apertura dei dati non sia sempre e solo parallelo a quello di gestione dei dati ma pienamente integrato.
Un dato della PA destinato alla pubblicazione è frutto di una catena di processi nel corso della quale si generano ulteriori prodotti intermedi. Comprendere e governare la struttura di questa catena diventa elemento cruciale. Affinché tale attività non sia assunta come un mero adempimento tecnologico, a essa deve corrispondere:
- l’ottimizzazione dei processi esistenti all’interno dei quali l’Open Data deve far parte integrante;
- la dislocazione di soluzioni interoperabili che possano contribuire all’ottimizzazione dei processi;
- una riduzione nei costi e nei tempi di accesso al capitale informativo;
- una riduzione della complessità dei processi interni attraverso il consolidamento delle attività derivate da 1) e 2);
- l’ottimizzazione dei tempi e dei canali di comunicazione istituzionali relativi al capitale informativo verso risorse esterne all’amministrazione.
Il primo passo da compiere è quello di individuare una chiara data governance interna con professionalità strategiche e specifiche.
Ruoli e responsabilità¶
Di seguito si elencano i componenti di un possibile gruppo di lavoro orizzontale e inter-settoriale che un’amministrazione può costituire per avviare e gestire a regime il processo di gestione dei dati in generale e, nello specifico, di apertura dei dati. Dipendentemente dalle dimensioni delle amministrazioni, alcune figure professionali possono coincidere o possono essere ulteriormente distinte.
Gruppo di lavoro Open Data¶
Il gruppo che promuove l’uso e la diffusione degli Open Data. Esso riporta all’interno dell’amministrazione le novità inerenti il mondo dell’Open Government, media e valuta le esigenze di pubblicazione dati in base alle normative di riferimento, e ne cura la razionalizzazione rispetto agli altri processi di apertura del dato. Ha la responsabilità di pianificare e coordinare l’evoluzione continua dell’apertura dei dati nell’amministrazione, nonché dell’infrastruttura IT a supporto.
All’interno del gruppo di lavoro è bene prevedere figure che possano fornire il necessario supporto per l’analisi della qualità dei dati, per la definizione delle interfacce d’accesso ai dati, per la promozione di applicazioni sviluppate a partire dai dati pubblicati, fornendo anche nel caso esempi di servizi dimostrativi attraverso cui incentivare il riutilizzo.
Inoltre, il gruppo di lavoro si può occupare della formazione tecnica e concettuale all’interno dell’amministrazione sui temi legati al paradigma Open Data, anche sulla base delle linee guida pubblicate dall’Agenzia per l’Italia Digitale e sullo stato dell’arte degli Open Data dell’amministrazione. Alcuni membri del team (e.g., esperti di tecnologie Web, esperti GIS, esperti di tecnologie e strumenti per i Linked Data) possono occuparsi della gestione del processo di apertura del dato dal punto di vista IT.
Affinché il lavoro del Team Open Data possa essere incisivo all’interno dell’amministrazione, è importante che tale team si confronti con il livello più politico, sia per ottenere da questo le necessarie “spinte”, sia per offrire al decisore politico proposte e stimoli.
Nota
Infine, l’art. 17 del Codice dell’Amministrazione Digitale individua un ufficio dirigenziale generale responsabile per la transizione alla modalità operativa digitale e un difensore civico per il digitale che ha il compito di ricevere segnalazioni di violazione del CAD invitando l’ufficio a porvi rimedio. Si ritiene importante che il responsabile dell’ufficio suddetto (articolo 17 comma 1-ter) faccia parte del gruppo di lavoro open data, anche come figura di raccordo con il livello più politico e che il difensore civico operi in stretta collaborazione con il gruppo open data.
Responsabile Open Data (o Data Manager)¶
All’interno del team Open Data è nominato un responsabile. Tale figura permette da un lato di localizzare le competenze necessarie alla gestione delle attività Open Data entro un sistema autonomo di comunicazione e funzionamento, e dall’altro di integrare i processi relativi alle attività di trasparenza in modo parallelo e non seriale. Il responsabile Open Data deve quindi possedere sia le capacità operative di controllo di tale sistema, sia quelle amministrative di coordinamento con i processi già esistenti.
Insieme al team suddetto, conosce i dati dell’amministrazione nel loro insieme, redige linee guida operative per lo scambio dati tra le diverse figure coinvolte (si veda sotto), e pianifica la strategia di apertura dei dati raccolti e analizzati e le attività di diffusione dei dati. Infine, collabora e si coordina con il Responsabile della Trasparenza (quest’ultimo istituito ai sensi del D.lgs. n. 33/2013 e s.m.i) al fine di rafforzare vicendevolmente gli obiettivi da un lato di massimo riutilizzo dei dati pubblici di tipo aperto e dall’altro di trasparenza.
Responsabile della banca dati¶
All’interno dell’amministrazione è responsabile del procedimento amministrativo che popola la specifica fonte del dato, che ne cura la qualità e il relativo aggiornamento. Tipicamente un Dirigente o un Quadro, coordina un gruppo di persone che svolgono il loro lavoro quotidiano attorno alla fonte del dato. Ha anche il potere di decidere se modificare un certo dato sulla base di indicazioni pervenute ad esempio da cittadini che, vedendo il dataset, ne richiedono una versione evoluta.
Referente tecnico della banca dati¶
Si tratta tipicamente di un componente del gruppo coordinato dal responsabile della banca dati; esso deve avere conoscenze informatiche e svolge un ruolo operativo sul sistema gestionale afferente al dato. Inoltre, fornisce indicazioni circa il reperimento concreto dei dati dalla base dati, e cura il monitoraggio dei vari “connettori” che a partire dalla base dati espongono il dato come Open Data. Tipicamente riceve materialmente le segnalazioni dei cittadini sul dataset di propria competenza, e le smista eventualmente al Referente tematico per valutarne il contenuto, prima di chiedere al Responsabile della Banca Dati l’approvazione per eventuali azioni correttive strutturali sul dataset.
Referente tematico della banca dati¶
Si tratta di un esperto di dominio che conosce in modo approfondito l’ufficio e la storia dei dati su cui l’ufficio opera. Spesso propone nuovi dataset da esporre a partire dal sistema gestionale corrispondente e cura eventuali valutazioni di dominio o relative al significato dei dati. Ha anche la possibilità di compiere bonifiche e semplici adeguamenti sulla banca dati, su segnalazione di cittadini o su valutazioni proprie. Riferisce invece al Responsabile della Banca dati la necessità di eventuali variazioni strutturali al sistema gestionale che insiste sui dati.
Ufficio Statistica¶
Un anello importante dell’intera catena, sia nel promuovere nuove tipologie di dataset da esporre, sia nel validare dal punto di vista metodologico e statistico i dati pubblicati e le loro visualizzazioni.
Ufficio giuridico-amministrativo¶
Può assumere le più svariate forme in base all’organizzazione interna dell’amministrazione. In generale esso rappresenta una singola figura che fornisce consulenza sia su aspetti non tecnici legati agli Open Data, come la definizione delle licenze e delle note legali associate ai dati, la loro rimodulazione sulla base di esigenze specifiche (si pensi per esempio alla necessità di aprire dati prodotti da terze parti o addirittura da cittadini), sia su tutte quelle problematiche di tipo giuridico o amministrativo, comprese quelle di privacy, di finalità del dataset e di trattamento del dato personale ove presente.
Gruppo comunicazione¶
Può assumere varie forme in base all’organizzazione interna dell’amministrazione, ma in ogni caso si indicano quelle figure con competenze di comunicazione istituzionale e non solo, in grado di curare la comunicazione e il dialogo con i cittadini.
Il Modello RACI¶
Rispetto alle linee di azione del modello operativo mostrato in Figura 5, e descritte di seguito, si individua la matrice dei Ruoli e delle Responsabilità (RACI) [3] tra le diverse figure identificate.
| Processo | Responsabile OD | Responsabile BD | Referente tecnico BD | Referente Tematico BD | Ufficio Statistica | Ufficio giuridico-amministrativo | Team comunicazione |
|---|---|---|---|---|---|---|---|
| Dati nativi | A/R | R | R | R | C | C | I |
| Dati mashup | A/R | C | R | C | C | C | I |
| Linked Open Data | R | A/R | R | R | C | C | I |
| Coinvolgimento | A | C | I | I | C | C | R |
Dove OD = Open Data, BD = Base Dati e
- Responsible (R): Coloro che lavorano per eseguire un determinato compito. Esiste almeno un ruolo di responsabile.
- Accountable (A): Il solo che può approvare il corretto completamento di un compito e che delega il lavoro ai responsabili. Può esistere un solo ruolo accountable per uno specifico compito.
- Consulted (C): Coloro che possono essere consultati in quanto esperti di dominio e con i quali instaurare una comunicazione bidirezionale.
- Informed (I): Coloro che devono essere tenuti aggiornati sui progressi del processo, spesso al termine dello stesso.
Bibliografia
| [3] | A Guide to the Project Management Body of Knowledge (PMBOK Guide). PMI Standards Committee, Project Management Institute. 2010. ISBN 1-933890-66-5. |
I processi del modello operativo¶
Di seguito sono riportati i processi organizzativi per ciascuna linea d’azione del modello presentato in Figura 5.
Linea 1: Dati Nativi¶
La linea 1 dei dati nativi tratta tutta la filiera di gestione ed esposizione dei dati esistenti generati dalle amministrazioni. Questi dati sono principalmente prodotti dai vari uffici durante l’adempimento delle proprie funzioni istituzionali. La maggior parte di questi dati possono essere pubblicati come dati aperti, portando un’ineludibile fonte potenziale di sviluppo per il territorio e per l’intero sistema Paese.
Censimento. All’interno dei singoli uffici o dei vari settori dell’amministrazione vanno quindi ricercate quelle che si possono chiamare “basi di dati primarie” oggetto del censimento. Si tratta di individuare quegli uffici che generano, mantengono e sono responsabili delle specifiche tipologie di dati che si vogliono rendere aperti (e.g., lo sportello unico per le attività produttive (SUAP) del comune è lo strumento che va a semplificare gli adempimenti connessi alla creazione, l’avvio, la modifica e la cessazione delle imprese per la produzione di beni e servizi. L’ufficio SUAP gestisce e mantiene quindi l’archivio con i dati di tutte le imprese del territorio).
Nota
Si raccomanda al responsabile Open Data di effettuare una ricognizione interna, alla luce della normativa vigente, in collaborazione con i responsabili delle basi di dati, al fine di individuare l’insieme di dati esistenti pubblicabili in formato aperto. Ciascun soggetto preposto alla gestione di una particolare base di dati indica al responsabile Open Data, tra le altre cose, le caratteristiche descrittive del dato, i tracciati record, il tasso temporale di aggiornamento, e ogni altra informazione utile a far comprendere le caratteristiche peculiari dei dati.
In quelle realtà in cui il processo di apertura dei dati ha raggiunto una fase matura, il concetto di dato nativo può evolvere, includendo non solo i dati raccolti perché legati all’attività amministrativa, ma anche tutte quelle informazioni che, una volta aperte, possano abilitare nuove forme di riutilizzo dell’informazione. Per esempio, se finora per un ufficio non era prioritario raccogliere in maniera strutturata un certo tipo di dato (e.g., gli esercizi che vendono prodotti a km zero o i locali che hanno prodotti per celiaci), perché non strettamente correlato a qualche norma o regolamento amministrativo, il solo fatto che un dato “nativo” poi viene aperto e reso fruibile in forme strutturate al cittadino, lo rende un dato utile all’attività istituzionale nel concetto “esteso” della pubblica amministrazione, inteso non solo come soggetto erogatore di servizi pubblici, ma anche come espositore di patrimonio informativo che abilita nuove forme di business sul mercato. I dati aperti, quindi, modificano il concetto stesso di utilità del dato inserendo nella categoria dei dati “nativi” della PA informazioni che prima non erano ritenute tali dalla PA stessa, ma che risultano invece utili all’esterno.
Nota
Si raccomanda quindi l’adozione di un approccio di tipo “demand- driven” per individuare i dati nativi che tenga conto dell’impatto economico e sociale nonché del livello di interesse degli utilizzatori suddivisi opportunamente per categorie (e.g., cittadini, imprese, altre pubbliche amministrazioni), dei loro requisiti e delle loro necessità.
A tal riguardo si evidenzia che il titolare del dato, ai sensi dell’articolo 5 comma 2 del D.lgs 36/2006 come modificato dal D.lgs 18 maggio 2015, n. 102 e s.m.i., stabilisce le modalità di acquisizione delle richieste con proprio provvedimento, instaurando così una collaborazione con le suddette categorie che possono sfruttare tali modalità per avanzare le proprie proposte.
Analisi giuridica delle fonti. Alla fase di censimento fa seguito l’analisi giuridica delle fonti del dato. Essa è fondamentale per garantire sostenibilità nel tempo del processo di produzione e pubblicazione dei dati e creare un servizio equilibrato nel rispetto della funzione pubblica e dei diritti dei singoli individui. L’analisi giuridica delle fonti mira quindi a valutare questi delicati equilibri, evidenziando limitazioni d’uso, finalità di competenza, determinazione dei diritti e dei termini di licenza.
Nota
Si riporta di seguito una breve “check list”, utile per verificare se tutti gli aspetti giuridici sono stati valutati dal responsabile della banca dati in collaborazione con il responsabile Open Data. La check list è formata da una serie di domande, per ciascun aspetto, a cui rispondere con Sì o No.
| Aspetto | Domanda |
|---|---|
| Privacy | i dati sono liberi da ogni informazione personale che possa
identificare in modo diretto l’individuo (nome, cognome, indirizzo,
codice fiscale, patente, telefono, email, foto, descrizione fisica,
ecc.)? In caso negativo queste informazioni sono autorizzate per
legge?
|
| Privacy | i dati sono liberi da ogni informazione indiretta che possa
identificare l’individuo (caratteristiche personali che possono
identificare facilmente il soggetto)? In caso negativo queste
informazioni sono autorizzate per legge?
|
| Privacy | i dati sono liberi da ogni informazione sensibile riconducibile
all’individuo? In caso negativo queste informazioni sono
autorizzate per legge?
|
| Privacy | i dati sono liberi da ogni informazione relativa al soggetto che
incrociata con dati comunemente reperibili nel web (e.g. google
maps,linked data, ecc.) possa identificare l’individuo? In caso
negativo queste informazioni sono autorizzate per legge?
|
| Privacy | i dati sono liberi da ogni riferimento a profughi, protetti di
giustizia, vittime di violenze o in ogni caso categorie protette?
|
| Privacy | hai considerato il rischio di de-anonimizzazione del tuo dataset
prima di pubblicarlo?
|
| Privacy | esponi dei servizi di ricerca tali da poter filtrare i dati in modo
da ottenere un solo record geolocalizzato, che sia facilmente
riconducibile ad una persona fisica?
|
| Proprietà intellettuale della sorgente | il dataset è stato creato da uno o più dipendenti della tua
pubblica amministrazione nell’ambito della loro attività lavorativa?
I singoli elementi del dataset suscettibili di autonoma protezione
(es., immagini, fotografie, testi in qualche modo creativi) sono stati
a loro volta prodotti da uno o più dipendenti della tua pubblica
amministrazione nell’ambito della loro attività lavorativa?
|
| Proprietà intellettuale della sorgente | l’amministrazione è proprietaria dei dati, anche se non sono stati
creati direttamente da suoi dipendenti??
|
| Proprietà intellettuale della sorgente | sei sicuro di non usare dati per i quali vi è una licenza o un
brevetto di terzi?
|
| Proprietà intellettuale della sorgente | se i dati non sono della tua amministrazione hai un accordo o una
licenza che ti autorizzi a pubblicarli?
|
| Licenza di rilascio | stai rilasciando i dati di cui possiedi la proprietà accompagnati da
una licenza?
|
| Licenza di rilascio | hai incluso anche la clausola di salvaguardia «Questo dataset
contiene informazioni indirettamente riferibili a persone fisiche.
In ogni caso, i dati non possono essere utilizzati al fine di
identificare nuovamente gli interessati.»?
|
| Limiti alla pubblicazione | hai verificato che non vi siano impedimenti di legge o contrattuali
che per la pubblicazione dei dati?
|
| Segretezza | hai verificato se non vi siano motivi di ordine pubblico o di
sicurezza nazionale che ti impediscono la pubblicazione dei dati?
|
| Segretezza | hai verificato se non vi siano motivi legati al segreto d’ufficio
che impediscono la pubblicazione dei dati?
|
| Segretezza | hai verificato se non vi siano motivi legati al segreto di
stato che impediscono la pubblicazione dei dati?
|
| Temporalizzazione | i dati sono soggetti per legge a restrizioni temporali di
pubblicazione?
|
| Temporalizzazione | i dati sono aggiornati frequentemente in modo da sanare eventuali
informazioni lesive di persone o organizzazioni?
|
| Temporalizzazione | i dati hanno dei divieti di legge o giurisprudenziali che
impediscono la loro indicizzazione da parte di motori di ricerca?
|
| Trasparenza | i dati rientrano nella lista dell’allegato A del d.lgs. 33/2013?
Se sì come sono stati trattati dal responsabile della trasparenza
nella sezione “Amministrazione trasparente”?
|
Analisi della qualità dei dati. All’analisi giuridica delle fonti segue l’analisi della qualità dei dati. Per la definizione del concetto generale di qualità si può ricorrere alla norma ISO 9000:2015, secondo cui la qualità è la totalità degli elementi e delle caratteristiche di un prodotto o servizio che concorrono alla capacità dello stesso di soddisfare esigenze espresse o implicite. Nella sezione dedicata alla “qualità dei dati” di seguito riportata si identificano alcune misure e un metodo di valutazione, considerando gli standard ISO di riferimento ISO/IEC 25012 e lo standard ISO/IEC 25024.
Bonifica. Generalmente l’analisi della qualità del dato può richiedere una fase di bonifica. Infatti, i dati all’interno dei sistemi informativi o degli archivi di un’amministrazione sono spesso “sporchi” e non rispondenti ai requisiti di qualità (e.g., accuratezza, completezza, ecc.). L’apertura dei dati può essere uno stimolo importante per la conduzione di attività mirate di bonifica. Si distinguono processi di bonifica basati sui dati e basati sui processi. I processi di bonifica basati sui dati prevedono che il dataset sia corretto in uno dei due seguenti modi: (i) confronto con il mondo reale (anche con attività economicamente onerose come contattare direttamente i soggetti preposti alla gestione della base dati che presenta errori per correggerli insieme loro) e (ii) confronto incrociato (matching) con altri dataset. Tali processi hanno il vantaggio di poter pervenire in termini relativamente brevi al risultato, ma lo svantaggio di non risolvere il problema alla radice. Infatti, in un arco temporale medio-lungo, i dataset potrebbero nuovamente presentare i problemi di qualità. I processi di bonifica basati sui processi hanno invece la caratteristica di analizzare le cause che hanno portato alla scarsa qualità del dato e di rivedere i processi di produzione del dato per garantirne la qualità nel tempo. Per esempio, se si riscontra che la scarsa accuratezza di una base di dati deriva da un processo di “data entry” manuale, si può intervenire prevedendo una fase di acquisizione automatica dei dati che minimizzi la possibilità di errore di acquisizione. L’adozione di processi di bonifica “basati sui processi” ha dunque il consistente vantaggio di essere una strategia risolutiva.
Politiche di accesso e licenza. Altro aspetto importante da considerare sono eventuali forme di aggregazione dei dati e restrizioni di accesso, che hanno anche un impatto sulla scelta della licenza, tappa quest’ultima prevista dal modello operativo e trattata ampiamente in “Aspetti legali e di costo” a cui si rimanda.
Nota
Sebbene sia sconsigliato restringere l’accesso ai dati o procedere con la pubblicazione di aggregazioni degli stessi (in generale non è opportuno che l’esposizione del dato lavorato avvenga senza che sia stato pubblicato prioritariamente il dato grezzo), esistono casi in cui i dati possono essere diffusi solo in forma anonima (ad esempio i redditi), ossia a un livello di aggregazione tale da impedire di identificare le persone cui i dati si riferiscono. A tal fine, è bene definire delle politiche di accesso ai dati in cui sia indicato un profilo di accesso specifico per ogni dato, dettato dai diritti sull’informazione di base, dalle norme o dalle policy in atto.
Analisi di processo, (re)ingegnerizzazione dei processi organizzativi e produzione dei dati. Ogni dato ha un proprio ciclo di vita, caratterizzato da uno specifico tasso di aggiornamento o manutenzione.
Nota
Risulta quindi necessario analizzare il processo organizzativo che produce e gestisce il dato per fare in modo che la produzione di quel dato sia consolidata e diventi stabile, secondo la frequenza di aggiornamento e le modalità di rilascio adottate.
Vanno quindi individuati non solo i dati nativi “grezzi” di partenza ma anche gli attori che concorrono alla prima produzione del dato, distinguendo chi è responsabile e titolare dello stesso e chi invece aggiunge altri elementi informativi nel processo produttivo. Quello che accade sovente nelle amministrazioni è che i dati sono gestiti da singoli funzionari, nell’ambito di processi “verticali” chiusi a livello di dipartimento e molto spesso ancorati alle conoscenze di una persona specifica. Accade così che elementi conoscitivi importanti siano delocalizzati tra i servizi di competenza, senza che tuttavia sussista una gestione federata e complessiva della risorsa dati. Questo fatto, tra i molteplici effetti negativi, ha spesso quello della duplicazione dei dati: uffici tematicamente contigui tendono a replicare informazioni funzionali alla propria attività, con un incremento del rumore di fondo attorno al patrimonio informativo dell’amministrazione. L’utilizzo di codici condivisi a livello nazionale, di classificazioni comuni per tipologie di dato non dipendenti da specifici domini e ll passaggio verso la creazione di una risorsa federata (fase data hub interno) consentono di superare progressivamente le suddette criticità. L’impegno politico e il relativo sostegno da parte dei livelli manageriali più alti costituiscono comunque il prerequisito fondamentale senza il quale ogni sforzo può essere vano.
Metadatazione. Il risultato delle precedenti tappe del modello operativo si traduce nella produzione di metadati che, in buona sostanza, certificano le caratteristiche del dato. Come detto precedentemente la metadatazione è cruciale: una delle peggiori malattie che affliggono i dati della PA è la molteplicità di copie disponibili di una stessa informazione, senza che sussista la necessaria certezza sulle caratteristiche e sulla validazione di ciascun rilascio. Si ricorda a tal riguardo di seguire il modello per i metadati descritto in “Modello per i metadati” e in particolare il profilo DCAT-AP_IT che consente di specificare i più importanti metadati descrittivi per i dataset (e.g., soggetti e relativi ruoli, contestualizzazione geografica e temporale, licenza, frequenza di aggiornamento, aspetti di distribuzione, punto di contatto, ecc.).
Data hub interno, produzione di livello 3, e pubblicazione. Nel modello operativo proposto, la risorsa federata è rappresentata dal cosiddetto data hub interno. Essa è una piattaforma dove far confluire tutti i dati prodotti dai diversi dipartimenti dell’amministrazione nella loro versione rilasciata ufficialmente. Questa infrastruttura, una volta attivata e messa a regime, viene a contenere lo stato dell’arte del patrimonio informativo e costituisce un potente punto di riferimento, accessibile da parte delle autorità di accesso, secondo diverse modalità (a “tag” o “query”). Essa, inoltre, costituisce lo snodo fondamentale, non solo per la linea dei dati nativi che può proseguire verso la produzione e la pubblicazione di dataset di livello 3, ma per tutte le altre direttrici indicate. In generale, il data hub interno, presumibilmente creato anche attraverso basi di dati consolidate e mantenute costantemente aggiornate attraverso l’inserimento di dati da parte dei funzionari dell’amministrazione, può essere agevolmente utilizzato per la gestione di un processo dinamico e sostenibile nel tempo di produzione di dati aperti, periodicamente aggiornati a ogni nuova revisione del data hub stesso. Infine, è bene notare che l’uso degli standard previsti per i livelli 4 e 5 del modello per i dati aperti (i.e., standard del Web semantico, come per esempio RDF e OWL descritti in “Architettura dell’informazione del settore pubblico”) può facilitare la definizione e la gestione del data hub interno, consentendo una più agevole integrazione tra i dati del patrimonio informativo.
Conservazione e storicizzazione. I dataset rilasciati costituiscono non solo una risorsa per la collettività, ma un prezioso patrimonio anche per le pubbliche amministrazioni che possono in questo modo archiviare in modo alternativo i loro dati in modalità indipendente dagli applicativi software originali che li hanno prodotti. Per questo motivo è importante premunirsi di un sistema di archiviazione/conservazione che mantenga le diverse versioni dei dati nel lungo periodo. A tal fine si raccomanda di assicurare che le versioni stesse siano accessibili a un URL stabile, che sia anche documentato unitamente alla pubblicazione del dato.
Linea 2: Dati Mashup¶
Oltre alla pubblicazione dei dati nativi, attività istituzionali multidisciplinari, che coinvolgono più di una pubblica amministrazione, potrebbero rendersi necessarie. Inoltre è cruciale la sensibilità dell’amministrazione rispetto agli stimoli e alle proposte provenienti dalla società civile. A tal riguardo, ogni nuovo dato in questa linea nasce da uno specifico “concept”. ovvero la proposta necessaria a definire gli elementi fondamentali di un progetto. All’interno di un “concept” si identifica l’idea generale e le linee guida del progetto che ne accompagnano la declinazione nel corso della fase esecutiva. Al “concept” fa seguito la raccolta delle informazioni dalle diverse fonti interne ed esterne che concorrono alla formazione del dato. Questa operazione di “mashup” (da cui il nome della linea) non implica soltanto la raccolta del dato da fonti diverse e la relativa definizione degli algoritmi di integrazione. La parte più importante è la definizione delle modalità di accesso a partire dalle politiche dei singoli produttori dei dati e le relative modalità di rilascio e aggiornamento dei dati. Questo tipo di dati, nati a seguito di particolari esigenze o di determinati disegni strategici, sono creati in funzione dell’esposizione al pubblico e del conseguente coinvolgimento. Per questo, essi si prestano a forme di coinvolgimento e visualizzazione (“data visualization”) particolarmente innovative che spesso sono definite già a livello di “concept”. Il risultato ultimo di questa linea è la produzione di API e/o la pubblicazione di altri dataset. In generale, si raccomanda di utilizzare un approccio di pubblicazione dataset/API, pubblicando come API sicuramente i dataset che necessitano di un aggiornamento dinamico e variabile, alleviando dall’onere dell’aggiornamento manuale.
Si noti infine che i risultati attesi da questa linea possono essere anche ottenuti con l’applicazione dei principi e metodologie previste per la linea 3 dei Linked Open Data, di seguito descritta, grazie ai collegamenti possibili tra i dati.
Linea 3: Linked Open Data¶
Nel modello operativo proposto in Figura 5, la linea Linked Open Data è raffigurata come una filiera di lavorazione autonoma in quanto considerata ancora per molte amministrazioni, soprattutto medio piccole, un percorso complesso da intraprendere, dove sono richieste competenze tecniche specifiche.
Nota
Tuttavia, l’intenzione delle presenti linee guida è quella di governare una transizione graduale verso la produzione nativa dei Linked Open Data e, le iniziative significative in merito da parte dell’ISTAT, dell’ISPRA, del Ministero dell’Economia e Finanze, del Ministero dell’Agricoltura del Ministero dei Beni e delle Attività Culturali e del Turismo, per citarne alcune, indicano che tale transizione può essere possibile, soprattutto se trainata da pubbliche amministrazioni centrali e regionali.
Nel modello operativo, vi è una chiara interconnessione tra la linea dei dati nativi e quella dei Linked Open Data. La connessione tra queste due linee (seppur non illustrata graficamente in Figura 5) è anche rafforzata dal fatto che alcune delle fasi attraversate dalla linea dei dati nativi sono necessarie per avviare, analogamente, il percorso sulla linea dei Linked Open Data. E” altresì importante notare che nella pratica si ritiene a volte necessario passare da modelli di rappresentazione tradizionali come quello relazionale per la modellazione dei dati operando opportune trasformazioni poi per renderli disponibili secondo i principi dei Linked Open Data. Tuttavia tale pratica non è necessariamente quella più appropriata: esistono situazioni per cui può essere più conveniente partire da un’ontologia del dominio e che si intende modellare e dall’uso di standard del Web semantico per poter governare i processi di gestione dei dati. Sebbene le linee guida della Commissione di Coordinamento SPC1 sull’interoperabilità semantica attraverso i Linked Open Data siano risalenti al 2012, la metodologia ivi proposta risulta essere ancora valida e solida per una produzione ottimale di Linked Open Data. Infatti, analizzando alcune fasi appartenenti alla linea dei dati nativi (i.e., censimento, analisi della qualità, bonifica e metadatazione) e alla linea dei Linked Open Data (i.e., modellazione, ontologia, inferenza, interlinking, validazione e pubblicazione) si nota come queste richiamino integralmente le sette fasi dell’approccio metodologico delle suddette linee guida. Si incoraggiano quindi le amministrazioni a riferirsi ancora a quel lavoro per affrontare il processo di produzione di Linked Open Data.
Linea 4: Coinvolgimento (Engagement)¶
Nota
AZIONE 7: DEFINISCI UNA CHIARA STRATEGIA DI COINVOLGIMENTO INTERNO ED ESTERNO
Si raccomanda alle amministrazioni di accompagnare il modello operativo con azioni di coinvolgimento degli stakeholder sia interni all’amministrazione che esterni. Il coinvolgimento interno può avvenire attraverso la diffusione della cultura dei dati di qualità e aperti, facendo comprendere l’impatto di questa diffusione anche in termini semplificativi delle procedure interne. Il coinvolgimento esterno passa in primo luogo dall’identificazione dei soggetti da coinvolgere (e.g., studenti universitari, soggetti preposti a indagini e analisi statistiche e/o economiche, startup e aziende). In secondo luogo esso passa dalla definizione della forma di coinvolgimento, da quella più semplice della comunicazione, anche interattiva, all’individuazione di scenari d’uso affiancati da forme più strutturate di coinvolgimento quali l’organizzazione di eventi per promuovere alcune tipologie di dataset e/o per analizzare casi d’uso, hackaton e app showcase.
Il percorso di coinvolgimento si relaziona facilmente anche con il noto modello internazionale a cinque stelle dell’engagement, proposto dal ricercatore inglese Tim Davies per attivare una strategia di rilascio di dataset aperti che sia il più possibile inclusiva. Il modello si compone dei seguenti livelli:

Essere guidati dalla domanda – pubblicare dati che soddisfino una domanda specifica di stakeholder esterni implica cominciare a ridurre le continue richieste di dati a un ufficio.

Inserire dati nel contesto – accompagnare i dati con una ricca documentazione ne permette un facile riutilizzo. Porli nel corretto contesto amplifica tale possibilità. Due ottimi esempi di implementazione di strategia di engagement di livello 2 vengono dal progetto recente Open Cantieri del Ministero delle Infrastrutture e dei Trasporti e dal progetto «OpenCoesione» del Dipartimento per lo Sviluppo e la Coesione Sociale. Il portale OpenCoesione presenta una grafica, corredata da una mappa e diagrammi, che permettono di prendere visione, in maniera efficace, della distribuzione dei fondi sociali europei sul territorio italiano. L’applicazione permette inoltre di scaricare i dati sia nella loro totalità, sia nello specifico caso dei progetti presentati o nelle loro aggregazioni per categoria o amministrazione comunale/provinciale/regionale.

Supportare conversazioni intorno ai dati – Molti cataloghi Open Data ospitano una sezione FAQ e offrono diversi canali di interazione quali email o social network attraverso cui dialogare con l’ente pubblico che distribuisce i dati. Nuovamente, il caso di OpenCoesione può essere visto come una buona iniziativa di coinvolgimento di questo livello in quanto offre la possibilità di usufruire di tali canali per innescare una conversazione online.

Creare capacità, competenze e reti – in questo livello rientra la fase “scenari d’uso” nel presentare i dati attraverso infografiche interattive si fornisce la possibilità di capire al meglio i dati. Rimane importante però stimolare il riutilizzo organizzando, ove possibile, incontri formativi volti a spiegare i dati e/o a mostrare strumenti di pulizia, analisi, e visualizzazione. Tra gli esempi virtuosi di tali pratiche rientrano “School of Data” dell’Open Knowledge Foundation, i datalab promossi da ISTAT e “A scuola di OpenCoesione” del Dipartimento per lo Sviluppo e la Coesione Sociale e del Ministero dell’Istruzione.

Collaborare su dati come una risorsa comune – il rilascio dei dati prevede cicli di feedback con una comunità di riferimento (spesso quella da cui si è partiti per aprire i dati) da cui trarne delle considerazioni e produrre nuovi dati e strumenti. Nuovamente, l’esempio di OpenCoesione fornisce iniziative virtuose di coinvolgimento a cinque stelle quali hackaton organizzati con la comunità e il progetto monithon.it dove, attraverso segnalazioni partendo dai progetti presentati nel sito di OpenCoesione, chiunque può riportare informazioni aggiuntive per stimolare evoluzioni dei progetti finanziati).
Coordinamento tra il livello nazionale e locale¶
Nota
AZIONE 8: FACILITA IL COORDINAMENTO TRA IL LIVELLO NAZIONALE E LOCALE ATTRAVERSO GLI OPEN DATA …
Diverse pubbliche amministrazioni centrali, al fine di adempiere a specifici obblighi normativi a loro assegnati o per dar seguito a impegni presi in iniziative internazionali (e.g., Open Government Partnership), hanno necessità di raccogliere dati provenienti dal livello di governo locale (e.g., SIOPE per la rilevazione telematica degli incassi e dei pagamenti di tutte le amministrazioni, ISTAT per le rilevazioni relative ai censimenti o ai numeri civici, Dipartimento della Protezione Civile che opera quasi esclusivamente sulla base di tale modello). In queste situazioni, si raccomanda alle amministrazioni di coordinarsi tra loro prima di intraprendere iniziative singole isolate. In particolare, le amministrazioni centrali possono assumere un ruolo di coordinatore e di promotore di apertura dei dati secondo i livelli più alti del modello per i dati aperti proposto dalle presenti linee guida, definendo anche schemi comuni secondo quanto descritto in “Architettura dell’informazione del settore pubblico”.
Si raccomanda poi di mantenere il colloquio, mediante scambio di dati, tra il livello centrale e locale attraverso l’uso dei dati aperti stessi, ove presenti, automatizzando quanto più possibile il processo di acquisizione da parte del livello centrale.
Con un eventuale supporto tecnico, su richiesta, di AgID, si consiglia inoltre di:
- identificare l’insieme minimo di dati rilasciati dal livello centrale, anche secondo quanto stabilito da disposizioni normative, e quelli che il livello locale può ulteriormente dettagliare per cogliere le specificità della propria realtà locale, abilitando ove possibile meccanismi automatici di collegamento tra i due insiemi. Questo consentirebbe di avere una vista nazionale e un unico punto di accesso centrale ai dati, e una vista locale e più specializzata offerta dal governo locale. Si noti che il paradigma dei Linked Open Data può essere particolarmente conveniente in questi casi in quanto il collegamento degli URI consentirebbe un’agevole integrazione dei dati e navigazione degli stessi da parte di programmi;
- documentare sia a livello centrale che locale i dati secondo il profilo nazionale per i metadati DCAT-AP_IT con l’aggiunta dei metadati di provenienza come precedentemente discusso, al fine di agevolare i possibili utilizzatori nel comprendere le diverse fasi di gestione del dato.
Qualità dei dati¶
Nota
AZIONE 9: GARANTISCI LE SEGUENTI DIMENSIONI DI QUALITA” DEI DATI …
Partendo dalle quattro caratteristiche, delle 15 previste dall’ISO/IEC 25012, individuate nella Determinazione Commissariale n. 68/2013 dell’AgID per le banche dati di interesse nazionale critiche, si garantisce il loro costante rispetto in tutto il processo di gestione e pubblicazione dei dati anche aperti. Queste quattro caratteristiche sono:
- accuratezza (sintattica e semantica) - il dato, e i suoi attributi, rappresenta correttamente il valore reale del concetto o evento cui si riferisce;
- coerenza - il dato, e i suoi attributi, non presenta contraddittorietà rispetto ad altri dati del contesto d’uso dell’amministrazione titolare;
- completezza – il dato risulta esaustivo per tutti i suoi valori attesi e rispetto alle entità relative (fonti) che concorrono alla definizione del procedimento;
- attualità (o tempestività di aggiornamento) - il dato, e i suoi attributi, è del “giusto tempo” (è aggiornato) rispetto al procedimento cui si riferisce.
Il miglioramento della qualità dei dati, e la maggiore diffusione delle tecniche di misurazione, dipende da vari fattori tra cui l’adesione a modelli di qualità condivisi. Il raggiungimento della qualità non è in ogni caso frutto di un impegno sporadico di singole amministrazioni, ma il frutto di una sinergia concertata che, basata su un cambio culturale, si apra a collaborazioni orizzontali che, pur nel rispetto della privacy, consentano un maggior dialogo tra le banche dati e razionalizzazione delle informazioni.
Per determinare la bontà dei dati è necessario definire delle misure attraverso le quali quantificare la qualità dei dati. Lo standard ISO/IEC 25012:2008, divenuto norma italiana UNI ISO/IEC 25012:2014, definisce un insieme di caratteristiche specifiche per la caratterizzazione della qualità dei dati: accuratezza, aggiornamento, completezza, consistenza, credibilità, accessibilità, comprensibilità, conformità, efficienza, precisione, riservatezza, tracciabilità, disponibilità, portabilità e ripristinabilità. Di queste caratteristiche, le presenti linee guida richiedono la garanzia di almeno quattro come elencate in azione 9, ovvero accuratezza, coerenza, completezza e attualità (o tempestività di aggiornamento). Il passo successivo è quantificarle in termini di misure, individuando delle soglie che consentano di discriminare la bontà o meno di un dato rispetto alla caratteristica in esame. La fase di valutazione della qualità dei dati è importante in tutti i sistemi informativi indipendentemente dall’apertura dei dati. Con l’adozione di politiche di apertura dei dati, la qualità dei dati assume un ruolo ancora più rilevante in quanto elemento per la certificazione della bontà dei dati forniti e soprattutto dell’appropriatezza rispetto all’utilizzo che del dato si vuole fare. L’ISO/IEC 25024 estende l’ISO/IEC 25012 “Data quality model” del 2008 al campo delle misurazioni, definendo 63 misure di qualità applicabili alle 15 caratteristiche di qualità dei dati, con le relative funzioni di calcolo. Per le quattro caratteristiche di qualità, messe in risalto dalla Determinazione Commissariale dell’Agenzia per l’Italia Digitale n. 68/2013, si riporta nella tabella seguente un insieme esemplificativo di misure, sulle 24 definite nello standard ISO per le stesse caratteristiche, a supporto delle attività di valutazione della qualità dei dati delle amministrazioni.
Caratteristiche di qualità¶
| Caratteristiche | Descrizione | Misure e funzioni di misura principali |
|---|---|---|
| Completezza | il grado per cui il
dato associato a
un’entità presenta
valori per tutti
gli attributi attesi
e relative istanze
in un certo contesto
|
Si individuano le i seguenti livelli di completezza:
1. completezza di schema: 1) percentuale di valori nulli
per concetti e proprietà rispetto al numero totale di valori
attesi;
2. completezza dei record: 2) numero di dati elementari
associati a un valore non nullo in un record, rispetto al
numero di dati elementari del record per cui può essere
misurata la completezza;
3. completezza di popolazione: percentuale di valori nulli
rispetto a una popolazione di riferimento.
Si noti che non sempre valori mancanti indicano
incompletezza. Per esempio: si supponga di considerare
dati relativi ai musei italiani e ai loro canali di contatto
(telefono ed email). Può capitare che i musei abbiano tutti
un indirizzo email ma non per tutti è presente un numero
di telefono.
|
| Accuratezza | Il grado in cui
gli attributi
rappresentano in
maniera corretta il
valore reale del
dato in uno
specifico contesto
|
Si individuano due tipi di accuratezza:
1. sintattica: ad esempio Girgia invece che Giorgia
2. semantica: ad esempio nel caso in cui si utilizzi
Gloria Sani intendendo invece un’altra persona e.g.,
Giorgia Sani
Una misura dell’accuratezza è data dalla ratio tra gli
attributi dei dati che hanno valori accurati
sintatticamente/semanticamente su il numero di attributi
dei dati per i quali è richiesta accuratezza
sintattica/semantica.
|
| Coerenza | Il grado in cui gli
attributi del dato
non sono in
contraddizione con
altri dati in uno
specifico contesto
|
Per poter valutare la coerenza una misura è quella che
consente di identificare le violazioni di regole semantiche
definite su alcuni elementi dei dati.
Per esempio, se una persona è “patentata” non può essere
possibile che la sua età sia “17 anni”.
Essa può essere calcolata come la ratio tra il numero di
attributi dei dati i cui valori sono semanticamente corretti
nel dataset sul numero di attributi dei dati per i quali
sono state definite delle regole semantiche.
Altra misura consiste nel rapporto tra il numero di valori
duplicati per ogni attributo della base dati e il numero
totale degli elementi della base dati.
|
| Tempestività | Il grado in cui gli
attributi del dato
sono al «giusto
tempo» rispetto al
contesto di
riferimento
|
La metrica è basata sull’uso dei metadati che indicano
quando il dato è stato aggiornato l’ultima volta.
Sulla base di questi metadati, si distinguono poi:
1. dati con periodicità di aggiornamento nota: in
questo caso 1) è possibile calcolare la tempestività in
maniera esatta identificando se la data di ultima modifica
del dato rispetto al tempo di misurazione ricade
nell’intervallo della frequenza di aggiornamento;
2. dati con periodicità di aggiornamento media:
in questo caso è possibile calcolare la tempestività
media con una percentuale di errore.
|
Certificati Open Data ODI¶
A completamento della suddetta analisi, si ricorda anche un’iniziativa nota dell’Istituto Open Data inglese (ODI) sui certificati Open Data. I certificati sono uno strumento utile per ottenere un’auto-certificazione sulla qualità dei dati prodotti e pubblicati. I certificati sono stati tradotti anche in italiano dal nodo dell’ODI di Trento. Per ottenere il certificato è necessario compilare un questionario online suddiviso in cinque macro- categorie che aiutano a identificare una scala di riutilizzo di un dataset. Queste sono: informazioni descrittive (molte delle quali già richieste dalle presenti linee guida), informazioni legali (che devono aver già trovato risposte positive ed esaustive mediante la “check list” proposta nella fase di analisi giuridica delle fonti), informazioni pratiche (e.g., reperibilità, note metodologiche, ecc.), informazioni tecniche e informazioni sociali. Le risposte alle domande producono un livello di certificazione che si distingue in: (i) “bronze”, che rappresenta una base per iniziare il processo di apertura dei dati; (ii) “silver”, dove il dato è documentato in un formato aperto e machine-readable e gli utilizzatori dei dati possono ricevere maggior supporto; (iii) “gold”, che fornisce le garanzie del livello precedente con ulteriori riguardanti l’aggiornamento costante e un più ampio supporto, (iv) “platinum”, che racchiude le garanzie gold, identificatori univoci dei dati; rappresenta quindi un’eccellente esempio di infrastruttura informativa.
Nota
Un analogo concetto ai certificati ODI è applicato nell’ambito del Data & Analytics Framework per i dataset (aperti e non) che esso tratta.