Architettura di alto livello¶
L’architettura logica del DAF è basata sui seguenti layers:
- Micro-Service Layer: composto da tutti i servizi necessari per implementare le funzionalità della piattaforma. Tutte le componenti sono implementate come microservizi.
- Ingestion Layer: dedicato alla realizzazione di tutte le attività utili al caricamento dei dati.
- Hadoop Computational Layer: contiene tutte le piattaforme computazionali che tipicamente fanno parte dell’ecosistema Hadoop, tra cui si evidenzia Spark sul quale si basano la maggior parte delle elaborazioni eseguite nel DAF. I microservizi presenti nel Micro-service layer utilizzano il livello computazionale per eseguire task utili all’accesso ai dati e alle operazioni di manipolazione e trasformazione. L’ingestion layer usa il computational layer per eseguire operazioni di conversione e trasformazione dei dati.
- Hadoop Storage Layer: ovvero la piattaforma di memorizzazione dei dati fornita da Hadoop. Benché tutti i dati del DAF siano memorizzati su HDFS (il filesystem distribuito del sistema Hadoop), a seconda delle esigenze è possibile che i dati siano replicati su Kudu e HBase per favorire l’efficienza computazionale dei tool di analisi.
L’immagine seguente riassume la vista logica dell’architettura del DAF:
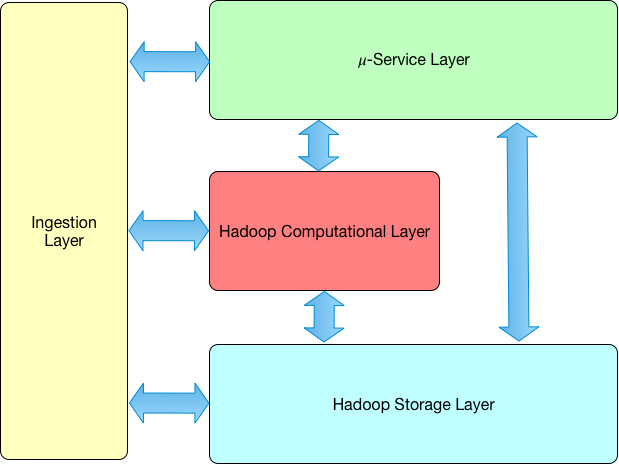
Fig. 1 Logical View
Dal punto di vista dell’architettura utile a ospitare il DAF, la piattaforma DAF è progettata per essere installata su due cluster disgiunti di macchine, così come mostrato nella figura successiva:
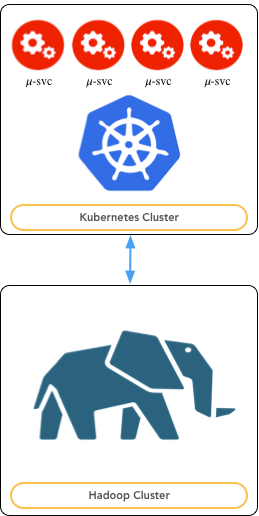
Fig. 2 Deployment View
In dettaglio:
- Kubernetes Cluster - ovvero un cluster Kubernetes composto da nodi che svolgono il ruolo di edge per il cluster Hadoop: tali nodi ospitano i microservizi che fanno, in modalità client, uso delle risorse computazionali e di memorizzazione offerte dal cluster Hadoop.
- Hadoop Cluster - ovvero un cluster di macchine su cui è installata una distribuzione Hadoop out-of-the-box in modalità multi-node.