Component/𝜇-Service View¶
The main components/𝜇-services of the DAF platform are:
The following image shows these components/𝜇-services and their mutual relationships.
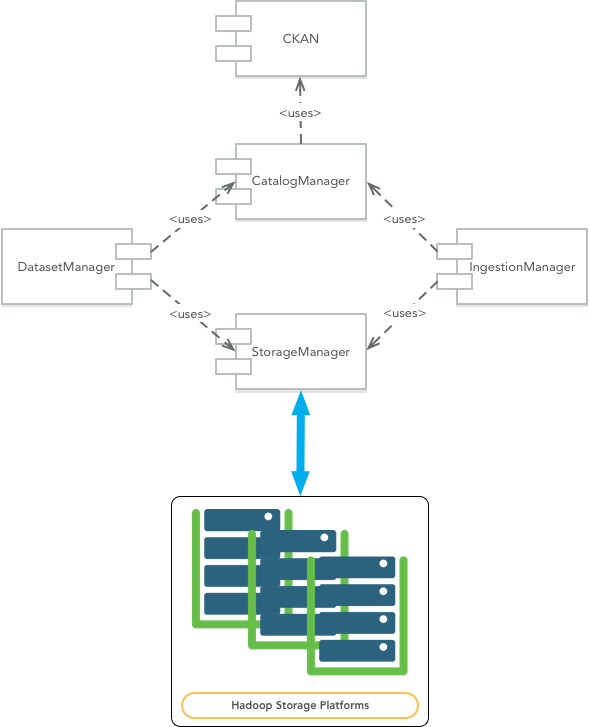
Fig. 3 Component View
CatalogManager¶
The CatalogManager is responsible for the creation, update and deletion of datasets in DAF. Furthermore, it takes care of the metadata information associated to a dataset.
The CatalogManager provides a common view and a common set of APIs for operating on datasets and on all related metadata information and schemas (see the CatalogManager API & endpoints).
The CatalogManager is based on the services provided by the CKAN service. In fact, one of the most relevant architectural decisions is to reuse as much as possible the metadata and catalog features provided by the CKAN service. The idea behind is simple: treating the data managed by the DAF platform similarly to what CKAN does with the open data. Part of the metadata are managed by the CKAN catalog and additional metadata information are managed by the CatalogManager.
The CatalogManager is also responsible to store all the schemas associated to the datasets: these schemas are saved as AVRO schemas.
IngestionManager¶
The IngestionManager manages all the data ingestion activities associated to datasets.
The IngestionManager collaborates with the CatalogManager to associate the proper metadata to the ingested data.
The IngestionManager provides an API to ingest data from a datasource into the DAF platfom (see the IngestionManager API & endpoints). In particular, the IngestionManager takes as input data and info needed to identify the dataset to which the data needs to be associated with. Before actually storing the data in DAF, the IngestionManager performs a set of coherence checks between the metadata contained in the catalogue and the data schema implied in the input data. There are two scenarios:
- The catalog entry for the dataset has been already set up. In this case the IngestionManager will check if the incoming data and schemas are congruent with what has been configured in the catalog.
- There is no catalog entry for the dataset. In this case the IngestionManager will automatically create an entry in the catalog checking that all the relevant information are provided during the ingestion phase.
The IngestionManager is also responsible for scheduling the ingestion tasks based on the information associated to the datasets. The ingestion for static data (data at rest) is based on a pull model. The dataset catalog entry should contain information about where and when the data should be pulled from.
StorageManager¶
The StorageManager is responsible for abstracting the physical medium where the data is actually stored (see the StorageManager API & endpoints).
The StorageManager is based on the Spark dataset abstraction for hiding the details of the specific storage platform. In fact, Spark provides a very powerful mechanism for describing a dataset source regardless of its actual physical place. We leverage this powerful mechanism for defining the physical URIs as described before, that is:
dataset:hdfs://for HDFS,dataset:kudu:dbname:tablenamefor Kudu,dataset:hbase:dbname:tablenamefor Hbase.
The only restriction we have to impose for making this Spark based mechanism working is to always have a dataset per HDFS directory.
DatasetManager¶
The DatasetManager manages operations several related to the dataset, such as:
- to return the data of the dataset (or a sample of it) in a specified format:
- to create a specific view on top of a dataset,
- to get the dataset schema in a given format (e.g. AVRO);
- to create a new dataset based on an existing one but saved into a different storage mechanism or based on a transformation of the existing dataset, etc.
For a list of endpoints and functionalities currently provided by the DatasetManager see the DatasetManager API & endpoints.
Technically speaking, the DatasetManager is responsible for all the tasks on top of the datasets, indicated by the logical URIs. For example tasks like format conversion, AVRO to Parquet, dataset import/movement, from HDFS to Kudu will be managed by this 𝜇-service.
The DatasetManager will interact with the CatalogManager for updating the information about the dataset is interacting with. For example, a format conversion means triggering a Spark job that creates first a copy of the source dataset in the target format. Then the catalog dataset is updated for taking into account the new dataset format.
The DatasetManager is also responsible for publishing the dataset into a proper serving layer. For example, a dataset operation could create an Impala external mapped on the dataset directory sitting on HDFS. This publishing operation will provide the user with the JDBC/ODBC connection informations for connecting an external tool to that table.