Architettura dell’Informazione del Settore Pubblico¶
Nota
AZIONE 10: RISPETTA L’ARCHITETTURA DELL’INFORMAZIONE DEL SETTORE PUBBLICO CON I RELATIVI STANDARD, FORMATI E VOCABOLARI…
Si adotta l’architettura dell’informazione del settore pubblico come mostrata in Figura 6. Per tutti i dati di riferimento e “core”, si raccomanda di non ridefinire degli schemi o modelli per i dati ma di riutilizzare quelli dell’architettura nazionale dell’informazione del settore pubblico, in larga parte allineati (collegati) a standard aperti del Web e disponibili in formati aperti standard. Questa raccomandazione si applica anche ai dati di domini verticali, dove, in alcuni casi, soprattutto per quelli riferibili alle base di dati chiave, ontologie/modelli per i dati saranno definiti e utilizzati nella rappresentazione delle basi di dati stesse.
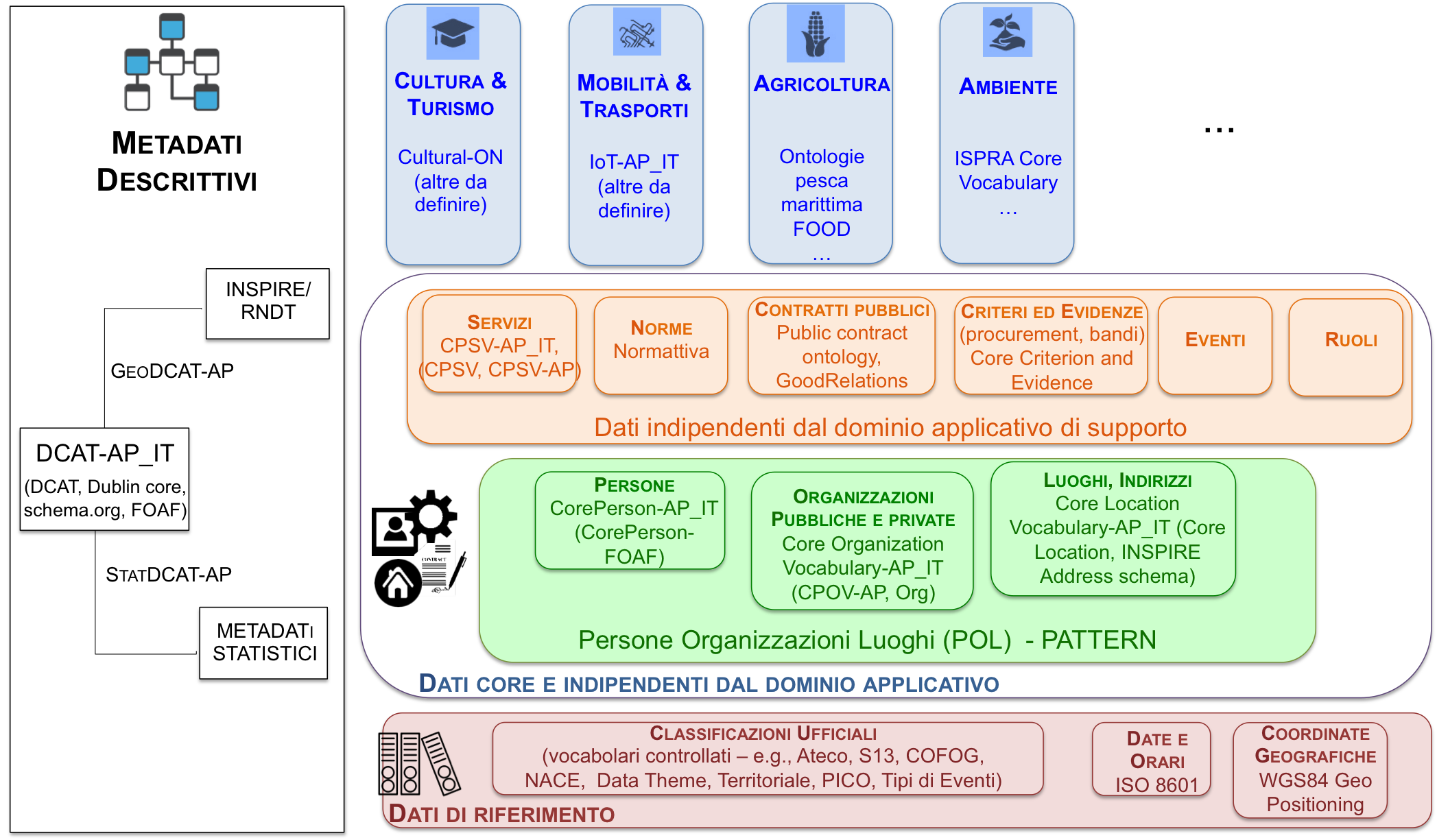
Fig. 6 Figura 6: Architettura dell’informazione del settore pubblico
La Figura 6 rappresenta un tentativo di delineare l’architettura di riferimento per l’informazione del settore pubblico.
Nota
La figura non ha la pretesa di essere esaustiva rispetto a tutte le tipologie di dati delle pubbliche amministrazioni ma ne classifica alcune, indicando per ognuna vocabolari/ontologie e vocabolari controllati, già anche sviluppati nel corso del 2017 grazie ai lavori della Task Force #DatPubblici. In particolare si segnala lo sviluppo del profilo applicativo IoT-AP_IT per la modellazione di eventi di tipo IoT (Internet of Things) che caratterizzano per esempio domini verticali quali quello della mobilità e del traffico (e.g., dati trasmessi in tempo reale da sensori del traffico). Sono attualmente in fase di sviluppo le ontologie del POL Pattern illustrato in Figura 6, mentre si raccomanda di utilizzare (i) l”ontologia DCAT-AP_IT per i metadati descrittivi dei dataset delle amministrazioni, (ii) l’ontologia CPSV-AP_IT per la modellazione dei servizi pubblici, utilizzata nello sviluppo del catalogo servizi.gov.it e (iii) l”ontologia Cultural-ON pubblicata dal Ministero dei Beni e delle Attività Culturali e del Turismo da utilizzarsi come riferimento nazionale per la modellazione dei luoghi e degli eventi della cultura. Tutte queste ontologie sono allineate ad altre note e disponibili nel Web (si utilizzerà lo spazio disponibile su Github per rilasciare le ontologie core e alcuni vocabolari controllati dell’architettura dell’informazione del settore pubblico).
Nei casi in cui non siano ancora presenti i relativi modelli nazionali, si incoraggiano le amministrazioni, al momento, a considerare i vocabolari noti e condivisi a livello internazionale indicati in Figura 6.
L’obiettivo della definizione di un’architettura dell’informazione del settore pubblico è quello di abilitare un processo di standardizzazione sia per la rappresentazione di dati ricorrenti, indipendenti dallo specifico dominio applicativo, come per esempio i dati sulle persone, sulle organizzazioni pubbliche e private, sui luoghi e gli indirizzi (POL pattern), sia per la rappresentazione di dati più settoriali che sono presi come riferimento in iniziative quali l’apertura delle basi di dati chiave o la pubblicazione di dati nella sezione «Amministrazione Trasparente».
Si ritiene questo possa facilitare la creazione di collegamenti tra dati (in figura 6 sono riportati vocabolari e classificazioni già disponibili anche secondo il paradigma dei Linked (Open) Data), portando alla costruzione di una grande base di conoscenza dell’informazione del settore pubblico da utilizzare per lo sviluppo di servizi nuovi e proattivi.
Nell’architettura si identificano due livelli: dati di riferimento e dati core e indipendenti dal dominio applicativo. Essi consistono di quei dati identificati univocamente e necessari per gestire e utilizzare in maniera affidabile infrastrutture di interesse nazionale e per interfacciare più agevolmente altri dati dipendenti da domini verticali. Il livello dei “dati di riferimento” consiste, in particolare, di tutte le classificazioni ufficiali che si raccomanda di utilizzare in quanto di riferimento per svariati contesti, e di dati relativi a informazioni sul tempo (e.g., date e orari) e geografiche (e.g., coordinate geografiche). Nell’ambito di questo livello si evidenziano classificazioni come quella territoriale, rilasciata dall’ISTAT anche sotto forma di LOD, quella sui temi (o domini), applicabile sia al contesto dei dati che a quello dei servizi, quella relativa alle funzioni amministrative/di governo (COFOG), anch’essa disponibile secondo il paradigma LOD e già adottata nell’ambito del bilancio pubblico, quella sulle tipologie di eventi pubblici recentemente creata, per citarne alcune. Infine, per i dati temporali e geografici comuni, come indicato in Figura 6, si raccomanda, rispettivamente, l’uso dello standard ISO 8601 e del vocabolario del W3C per la definizione delle coordinate geografiche.
Il livello dei “dati core e indipendenti dal dominio applicativo” (o dati core orizzontali) consiste dell’insieme di tipologie di dati riferibili principalmente a soggetti, luoghi, organizzazioni, servizi e altri asset e requisiti tipici della pubblica amministrazione. A oggi, sono state individuate tre tipologie di dati “core” principali, come rappresentate in Figura 6: persone, organizzazioni pubbliche e private, luoghi e indirizzi. A queste si aggiungono i «dati indipendenti dal dominio applicativo a supporto» ovvero dati che, insieme ai dati core, contribuiscono a descrivere i contesti tipici delle amministrazioni. Questi sono per esempio i contratti pubblici, i criteri e le evidenze - ovvero requisiti utilizzati per giudicare o prendere decisioni nonché prove che qualcosa è avvenuto o che criteri specifici sono stati rispettati da parte di soggetti - norme, eventi, ruoli. Molte di queste tipologie sono direttamente collegabili a banche dati di interesse nazionale; per esempio, la tipologia “persone” si collega all’Anagrafe Nazionale della Popolazione Residente (ANPR), la tipologia “luoghi e indirizzi” è correlata all’Anagrafe Nazionale dei Numeri Civici e delle Strade Urbane, la tipologia “contratti pubblici” è connessa alla banca dati di interesse nazionale sui contratti pubblici, e così via.
L’architettura dell’informazione del settore pubblico adotta nello specifico i cosiddetti “Core Vocabulary”, definiti dalla commissione europea nell’ambito del programma ISA e ISA2 sull’interoperabilità semantica, e in parte standardizzati dal W3C. In particolare, per i dati core e alcuni dati indipendenti dal dominio (come nel caso dei criteri ed evidenze per cui si raccomanda l’uso del vocabolario Core Criterion and Evidence) la metodologia di definizione del modello per i dati è la stessa adottata per la creazione del profilo di metadatazione nazionale DCAT-AP_IT e per quello sui servizi pubblici CPSV-AP_IT: partendo dal vocabolario definito nell’ambito europeo, e partendo dal relativo profilo applicativo (AP), ove necessario, si estende il profilo europeo con ulteriori metadati che consentano di rappresentare i dati disponibili nell’amministrazione italiana. Nell’effettuare l’estensione è necessario assicurarsi di mantenere l’interoperabilità con il profilo europeo e quindi non rimuovere eventuali vincoli e rispettare l’uso di vocabolari controllati indicati.
A partire dai livelli dell’architettura sopra citati, è possibile collocare e costruire modelli per dati specifici di domini verticali. In Figura 6 sono mostrati solo alcuni domini a titolo di esempio, con l’indicazione di vocabolari in taluni casi già sviluppati da amministrazioni centrali. E” il caso del Ministero dei Beni e Attività Culturali e del Turismo (MIBACT) che ha deciso di adottare la suddetta ontologia Cultural-ON per i luoghi e gli eventi culturali; è il caso dell’ISPRA che ha rilasciato una piattaforma LOD con le ontologie per i dati sul consumo del suolo, sulla rete mareografica e ondametrica e sui sistemi di cartografia che, grazie anche ai collegamenti abilitati tramite il paradigma Linked Data, sono stati collegati con successo alla classificazione territoriale di riferimento pubblicata dall’ISTAT.
L’architettura si compone poi del livello verticale dei metadati descrittivi che coinvolge tutti i tipi di dati fin qui discussi. Punto di riferimento per i metadati descrittivi è DCAT-AP_IT con le sue estensioni per i dati geografici e statistici che consentono un raccordo con i rispettivi profili come definiti nel contesto del Repertorio Nazionale dei Dati Territoriali (RNDT) e dall’ISTAT.
L’architettura di riferimento per l’informazione del settore pubblico si completa con l’indicazione degli standard e dei formati, descritti di seguito, che possono essere utilizzati per rappresentare i dati che la compongono.
Nota
Si raccomanda in generale di rendere disponibili in forma Open Data tutti i dati di riferimento. Si raccomanda altresì di prediligere tale paradigma per i dati core indipendenti dal dominio, prestando attenzione ai dati a conoscibilità limitata e ai dati personali per i quali il paradigma non può applicarsi (si veda “Dati della Pubblica Amministrazione”).
Standard di riferimento¶
I principali standard di riferimento per l’architettura dell’informazione del settore pubblico, necessari anche ad abilitare i livelli 4 e 5 del modello dei dati e i livelli 3 e 4 del modello dei metadati derivano dalle esperienze maturate dagli esperti nel settore del Web Semantico, con la visione di trasformare il Web in un unico spazio informativo globale. Essi sono riportati nel seguito.
RDF (Resource Description Framework)¶
È un framework per la rappresentazione dell’informazione nel Web e uno degli standard alla base del Web Semantico. Esso consente di catturare la semantica dei dati, quindi la loro comprensibilità, facilitandone l’accessibilità da parte di agenti automatici tramite l’infrastruttura e i protocolli Internet esistenti. In una concezione astratta della realtà, ogni oggetto e ogni entità (reale o virtuale) sono risorse. Associando a ogni risorsa un identificativo univoco, nello specifico un URI (Uniform Resource Identifier), si rappresentano nel Web le informazioni relative alle risorse, rendendole accessibili e riferibili da tutti.
Tecnicamente, RDF è un framework concettuale che consente, sfruttando la suddetta identificazione delle risorse, di descriverle mettendole in relazione tra loro. RDF ha un solo costrutto informativo di base, la cosiddetta tripla <soggetto> <predicato> <oggetto>. Un soggetto è sempre una risorsa (i.e., il suo URI), un oggetto è una risorsa o un valore (in quest’ultimo caso un’espressione puramente simbolica come un numero, una stringa, una data, ecc.), un predicato è una relazione, cui è associato un tipo, tra due risorse o una proprietà di una risorsa. Si noti che anche i predicati sono rappresentati con URI. In questo modo le risorse sono descritte tramite delle relazioni aventi un significato ben preciso e inserite in un particolare contesto. Le triple RDF sono strutture ricorsive, soggetto-verbo-oggetto (come nel caso del linguaggio naturale). La concatenazione di triple genera un “grafo RDF”; pertanto, un insieme di dati rappresentati attraverso il framework RDF è un grafo. Lo spazio Web in cui dati RDF sono localizzati è il cosiddetto Web dei Dati (“Web of Data”), mentre la sua prospettiva, focalizzata maggiormente sul contenuto informativo, è detta Web Semantico. RDF può essere implementato attraverso diverse forme sintattiche, anche dette serializzazioni, quali RDF/XML, Notation3, N-Triple, Turtle e JSON-LD (si veda sotto). La scelta tra le diverse soluzioni sintattiche deve essere fatta sulla base di requisiti richiesti quali compattezza, spazio fisico utilizzato, leggibilità, ecc. Le serializzazioni sono comunque fra loro inter-traducibili. Infine, esiste la possibilità di poter includere informazioni RDF all’interno di pagine Web mediante il formalismo RDFa (RDF in Attributes).
RDFS (RDF Schema)¶
È un’estensione di RDF che permette di definire semplici schemi per i dati. Lo standard introduce alcuni costrutti come le classi (rdfs:Class), le collezioni (ad esempio, rdfs:List) e una serie di proprietà per poter definire tassonomie e relazioni tra classi e proprietà (ad esempio, rdfs:subClassOf, rdfs:subPropertyOf). In pratica, con RDFS si possono gestire relazioni insiemistiche, ereditarietà e vari tipi di vincoli. Gli schemi definiti con RDFS sono comunemente detti ontologie.
OWL (Ontology Web Language)¶
Mentre RDFS consente di definire semplici schemi per dati RDF, schemi più evoluti possono essere definiti tramite OWL, uno standard W3C che arricchisce RDFS con ulteriori formalismi, includendo semantica formale e logica descrittiva. Un’ontologia consente in modo preciso ed efficace di modellare un dominio di interesse, quindi i suoi oggetti e le relazioni tra questi. In pratica, OWL fornisce il pieno supporto alla definizione di ontologie. Molte ontologie, nate per rappresentare le informazioni di domini ben precisi, sono note e condivise globalmente. Questa condivisione agevola la comprensione e il riutilizzo di schemi e metadati, abilitando di conseguenza l’interoperabilità semantica tra sistemi differenti. L’aspetto logico delle ontologie fornisce la possibilità di verificare automaticamente la correttezza logica di ciò che si rappresenta. Inoltre i cosiddetti ragionatori automatici per le logiche descrittive consentono di inferire, sui dati conformi all’ontologia, nuove triple e quindi informazione addizionale.
SPARQL (Sparql Protocol And Rdf Query Language)¶
Tra le diverse proposte di linguaggi di interrogazione per dati RDF, il W3C ha standardizzato SPARQL. Una semplice interrogazione SPARQL si compone di una concatenazione di triple in cui alcuni elementi possono essere delle variabili incognite. L’esecuzione di una interrogazione SPARQL cerca tra i dati le concatenazioni di triple “conformi” a quelle dell’interrogazione, assegnando (i.e., istanziando) degli URI o dei valori alle variabili che possono anche essere restituiti in output. È anche possibile specificare operazioni di manipolazione dei dati, come ad esempio istruzioni di “insert”, “update” e “delete”. SPARQL non è solo un linguaggio di interrogazione ma è un protocollo completo per l’accesso ai dati in quanto definisce anche le modalità con cui le interrogazioni possono essere eseguite via Web (appoggiandosi al protocollo HTTP) e come i risultati devono essere restituiti all’utente. I servizi Web che implementano il protocollo SPARQL sono detti SPARQL endpoint.
SDMX (Statistical Data and Metadata eXchange)¶
È uno standard ISO per lo scambio di dati statistici basato su sintassi XML. Esso implementa al suo interno un modello dati per la rappresentazione di dati multidimensionali. Pertanto descrive la struttura di un particolare “dataflow” attraverso un insieme di dimensioni (e.g., territorio o tempo), un insieme di attributi (e.g., unità di misura) e le classificazioni associate. Si nota che sebbene SDMX sia nato come modello per lo scambio di dati, esso viene anche usato per la loro rappresentazione.
Formati aperti per i dati e documenti¶
Nota
AZIONE 11: SELEZIONA I FORMATI CHE MEGLIO SI ADATTANO AL CONTENUTO E AI DATI DA CONDIVIDERE E RILASCIARE …
Si adottano formati aperti senza assumere che gli utenti possano leggere formati proprietari. Nel caso inevitabile di rilascio in formati proprietari, è necessario assicurare la disponibilità anche di un’alternativa non proprietaria. È necessario evitare di utilizzare un formato per dati non strutturati (e.g., PDF) in presenza di dati strutturati (e.g., è da evitare la pubblicazione di tabelle di tassi di assenza in PDF, privilegiando un formato come il CSV). Si raccomanda inoltre, nel rilasciare i dati secondo i formati sotto riportati, di specificare la codifica dei caratteri privilegiando, ove possibile, UTF 8. Infine, nel caso di rilascio programmato di dati, è da evitare l’uso di formati per dati non strutturati, privilegiando formati “machine-readable”.
Nel caso di documenti, sono da evitare scansioni di documenti cartacei in quanto non accessibili e quindi non aperti. In generale, si raccomanda di adottare, ove esistano, standard XML documentali internazionali o nazionali.
Formati aperti per i dati¶
XML (eXtensible Markup Language)¶
È un linguaggio di marcatura standardizzato dal W3C usato per l’annotazione di documenti e per la costruzione di altri linguaggi più specifici per l’annotazione di documenti (e.g., XBRL per la rappresentazione dei bilanci, Normattiva per la rappresentazione di documenti informatici in ambito giuridico, ecc.). Il mondo legato all’XML è molto ampio e la sua trattazione non rientra tra gli obiettivi del presente documento. Nell’ambito del Web Semantico è stata definita una specifica serializzazione RDF/XML.
N-Triples¶
È una serializzazione di RDF in cui ogni tripla è espressa interamente e indipendentemente dalle altre. La concatenazione delle triple di un dataset RDF secondo N-Triples avviene utilizzando il carattere punto (i.e., <soggetto1> <predicato1> <oggetto1> . <soggetto2> <predicato2> <oggetto2>).
Notation3¶
Notation3 (o N3) è una serializzazione RDF pensata per essere più compatta rispetto a quella ottenuta utilizzando la sintassi XML Essa risulta più leggibile da parte degli utenti e possiede delle caratteristiche che esulano dall’uso stretto di RDF (e.g., rappresentazione di formule logiche).
Turtle¶
È una versione semplificata (un sottoinsieme di funzionalità) di N3. Un dataset in Turtle è una rappresentazione testuale di un grafo RDF e, al contrario di RDF/XML, è di più facile lettura e gestione anche manuale.
JSON (JavaScript Object Notation)¶
È un formato aperto per la rappresentazione e lo scambio di dati semi-strutturati, leggibile anche dagli utenti e che mantiene, rispetto a formati simili come l’XML, una sintassi poco prolissa. Questo aspetto ne fa un formato flessibile e compatto. Esso nasce dalla rappresentazione di strutture dati semplici nel linguaggio di programmazione JavaScript, ma mantiene indipendenza rispetto ai linguaggi di programmazione.
JSON-LD¶
È un formato di serializzazione per RDF, standardizzato dal W3C, che fa uso di una sintassi JSON. Viene proposto come formato per Linked Data, mascherando di proposito la sua natura di serializzazione di RDF per ragioni di diffusione del formato. Il gruppo di lavoro che l’ha definito ha posto come obiettivo, oltre quello di mettere a disposizione un’ulteriore funzionalità al framework RDF, anche quello di avvicinare il mondo dello sviluppo Web e degli utilizzatori dei sistemi di gestione dati NoSQL (in particolare dei document store) al Web Semantico. Da un punto di vista pratico è possibile rilasciare dati RDF utilizzando questo «dialetto» JSON nelle situazioni in cui inizialmente non ci si possa dotare di tecnologie ad-hoc come triple store. Allo stesso tempo, con JSON-LD si fornisce uno strumento standard che consente il collegamento di documenti JSON che per loro natura sono unità di informazione indipendenti.
CSV (Comma Separated Values)¶
È un formato di file testuale utilizzato per rappresentare informazioni con struttura tabellare. Esso è spesso usato per importare ed esportare il contenuto di tabelle di database relazionali e fogli elettronici. Le righe delle tabelle corrispondono a righe nel file di testo CSV e i valori delle celle sono divisi da un carattere separatore, che di solito, come indica il nome stesso, è la virgola. Il CSV non è uno standard vero e proprio ma la sua modalità d’uso è descritta nell’RFC 4180. Nel rilascio di dati secondo il formato CSV, per agevolare i riutilizzatoti, si raccomanda di dichiarare almeno 1) il separatore di campo utilizzato (e.g, virgola, punto e virgola); 2) se è stato usato un carattere per delimitare i campi di testo. Nel corso del 2015, un gruppo di lavoro del W3C «CSV on the web» ha rilasciato una serie di standard del Web tra cui alcuni relativi ai meccanismi necessari a trasformare CSV in vari formati quali JSON, XML e RDF. Per gli scopi del presente aggiornamento delle linee guida, si raccomanda di considerare due standard: “Generating JSON from Tabular Data on the Web” e “Generating RDF from Tabular Data on the Web”.
Formati aperti più diffusi per i dati geografici¶
Shapefile¶
È il formato standard de-facto per la rappresentazione dei dati dei sistemi informativi geografici (GIS). I dati sono di tipo vettoriale. Lo shapefile è stato creato dalla società privata ESRI che rende comunque pubbliche le sue specifiche. L’apertura delle specifiche ha consentito lo sviluppo di diversi strumenti in grado di gestire e creare tale formato. Seppur impropriamente ci si riferisca a uno shapefile, nella pratica si devono considerare almeno tre file: un .shp contenente le forme geometriche, un .dbf contenente il database degli attributi delle forme geometriche e un file .shx come indice delle forme geometriche. A questi tre si deve anche accompagnare un file .prj che contiene le impostazioni del sistema di riferimento. Si raccomanda comunque di specificare nei metadati la proiezione utilizzata. È importante notare che non risulta ancora chiaro se tale formato lo si possa considerare propriamente aperto (e quindi coerente con la definizione introdotta dall’art. 68 del CAD) di livello 3 secondo il modello per i dati proposto nel presente documento. Questo è dovuto al fatto che, per alcune comunità, esso è un formato proprietario e quindi di livello 2, mentre per altre i dati possono essere gestiti attraverso una serie di strumenti non necessariamente confinati a determinate tipologie software (grazie alle specifiche tecniche aperte e pubbliche rese disponibili da ESRI). Tenuto conto dell’ampio uso di tale formato per la rappresentazione dei dati geografici si ritiene opportuno includerlo comunque in questo elenco.
KML¶
È un formato basato su XML per rappresentare dati geografici. Nato con Google, è diventato poi uno standard OGC. Le specifiche della versione 2.2 presentano una serie di entità XML attraverso cui archiviare le coordinate geografiche che rappresentano punti, linee e poligoni espressi in coordinate WGS84 e altre utili a definire gli stili attraverso cui visualizzare i dati. Eventuali attributi delle geometrie vanno espressi invece attraverso la personalizzazione di alcune entità. Molti strumenti di conversione non si occupano tuttavia di creare questa struttura dati e delegano gli attributi delle geometrie allo stile di visualizzazione. Si consiglia pertanto di distribuire questo dato prestando attenzione o, eventualmente, accompagnando il dataset assieme ad un altro formato aperto per i dati geografici (ad esempio, .shp, .geojson).
GeoJSON¶
È un formato aperto per la rappresentazione e l’interscambio dei dati territoriali in forma vettoriale, basato su JSON. Ogni dato è codificato come oggetto che può rappresentare una geometria, una caratteristica o una collezione di caratteristiche. A ogni oggetto è associato un insieme di coppie nome/valore (membri). I principali nomi di membri che rappresentano le caratteristiche dei dati geografici sono: «type» che serve a indicare il tipo di geometria (punto, linea, poligono o insieme multi-parte di questi tipi); «coordinates» attraverso cui sono indicate le coordinate dell’oggetto in un dato sistema di riferimento; «bbox» attraverso cui sono indicate le coordinate di un riquadro di delimitazione geografica; «crs» (opzionale) per l’indicazione del sistema di riferimento. Inoltre, è possibile associare all’oggetto specifici attributi, attraverso il membro con nome «properties». Si tratta di un formato molto diffuso e supportato da diversi software, ampiamente utilizzato in ambito di sviluppo web. Lo scorso agosto 2016 è stata pubblicata la relativa RFC 7946 “The GeoJSON Format”. La specifica raccomanda di limitare la precisione delle coordinate a 6 decimali, attraverso cui si può specificare qualsiasi posizione sulla terra con una tolleranza di 10 centimetri. La specifica inoltre richiede che i dati siano memorizzati con un sistema di riferimento di coordinate geografiche WGS 84, in latitudine e longitudine, nello stesso stile dei dati GPS.
GML (Geography Markup Language)¶
È una grammatica XML che rappresenta un formato di scambio aperto per i dati territoriali. Definita originariamente da OGC, e diventata poi lo Standard ISO 19136:2008, essa fornisce la codifica XML (schemi XSD) delle classi concettuali definite in diversi Standard ISO della serie 19100 e di classi aggiuntive quali: geometrie, oggetti topologici, unità di misura, tipi di base, riferimenti temporali, caratteristiche, sistemi di riferimento, copertura.
GeoPackage¶
È un formato aperto per la rappresentazione di dati geografici e può essere un’alternativa al suddetto formato shapefile. Esso supporta SpatiaLite ovvero un’estensione dello schema del database SQLite. Il principale vantaggio offerto da GeoPackage è quello di rappresentare in un unico file diversi dati geografici, sia di tipo vettoriale che raster, che possono essere gestiti anche tramite apposite interrogazioni SQL. Lo standard è riconosciuto dall’Open Geospatial Consortium.
Formati aperti per i documenti¶
L’articolo 1 del nuovo CAD definisce:
p) documento informatico: il documento elettronico che contiene la rappresentazione informatica di atti, fatti o dati giuridicamente rilevanti; p-bis) documento analogico: la rappresentazione non informatica di atti, fatti o dati giuridicamente rilevanti.
Il contesto normativo del recepimento della direttiva relativa al riutilizzo dell’informazione del settore pubblico (D.lgs 2006, 24 gennaio, n. 36 – art. 2), definisce il documento come «la rappresentazione di atti, fatti e dati a prescindere dal supporto nella disponibilità della pubblica amministrazione o dell’organismo di diritto pubblico. La definizione di documento non comprende i programmi informatici”.
ODF (Open Document Format)¶
È uno standard dell’OASIS che specifica le caratteristiche di un formato per documenti digitali basato su XML, indipendente dall’applicazione e dalla piattaforma utilizzata. La seguente serie di formati aperti è parte dello standard OASIS ODF:
- ODT (Open Document Text). Standard aperto per documenti testuali. È stato adottato come formato principale per i testi in alcune suite per l’automazione d’ufficio come OpenOffice.org e LibreOffice; è supportato da altre come Microsoft Office, Google Drive e IBM Lotus.
- ODS (Open Document Spreadsheet). Standard aperto per fogli di calcolo. Come nel caso precedente, è stato adottato come formato principale per i fogli di calcolo in alcune suite per l’automazione d’ufficio come OpenOffice.org e LibreOffice; è supportato da altre come Microsoft Office, Google Drive e IBM Lotus.
- ODP (Open Document Presentation). Standard aperto per documenti di presentazione. È stato adottato come formato principale per i documenti di presentazione in alcune suite per l’automazione d’ufficio come OpenOffice.org e LibreOffice; è supportato da altre come Microsoft Office, Google Drive e IBM Lotus.
PDF¶
È un formato aperto creato da Adobe per la rappresentazione di documenti contenenti testo e immagini che sia indipendente dalla piattaforma di lettura (applicativo, sistema operativo e hardware). È stato standardizzato dall’ISO (ISO/IEC 32000-1:2008) con una serie di formati differenti, ognuno avente una propria prerogativa (e.g., PDF/UA per l’accessibilità, PDF/H per documenti sanitari, PDF/A per l’archiviazione, ecc.). Si noti che rilasciare dati secondo tale formato limita fortemente il riutilizzo dei dati stessi in quanto l’intervento umano richiesto per la loro elaborazione è molto elevato (dati rilasciati in formato PDF con una licenza aperta rappresentano solo il primo livello del modello dei dati aperti).
Akoma Ntoso¶
È un linguaggio basato su XML per la rappresentazione di documenti giuridici. È in fase di approvazione presso il consorzio OASIS ed è utilizzato dal Parlamento Europeo e dalla Commissione Europea come standard documentale per i documenti legislativi, giuridici e allegati tecnici.