Modello per i metadati¶
Nota
AZIONE 4: CORREDA I DATI CON I RELATIVI METADATI …
La metadatazione ricopre un ruolo essenziale laddove i dati sono esposti a utenti terzi e a software. I metadati, infatti, consentono una maggiore comprensione e rappresentano la chiave attraverso cui abilitare più agevolmente la ricerca, la scoperta, l’accesso e quindi il riuso dei dati stessi. A tale scopo, si adotta il modello per i metadati rappresentato in Figura 3. Il modello si focalizza sugli aspetti qualitativi dei metadati, è indipendente dal particolare schema proposto e, in parte, anche dal formato fisico di rappresentazione. La classificazione qualitativa dei metadati si fonda su due fattori principali: legame tra dato-metadato e livello di dettaglio.
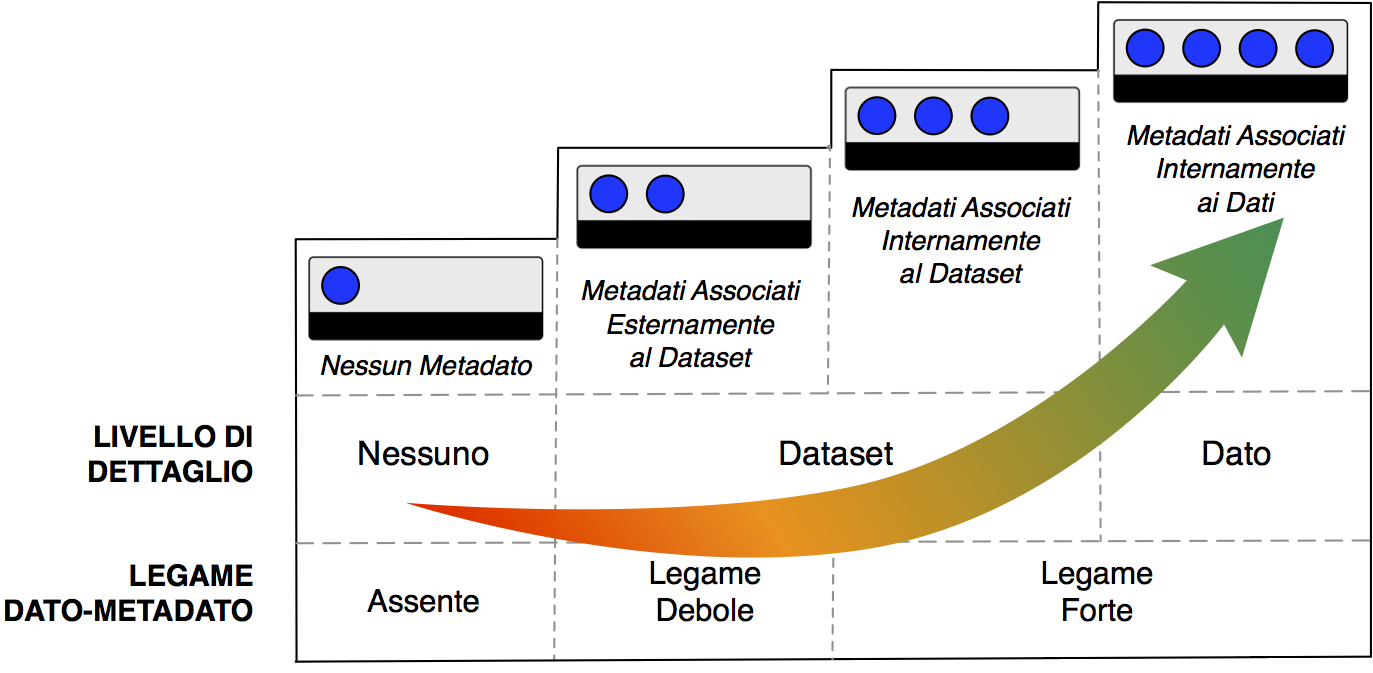
Fig. 3 Figura 3: Modello a quattro livelli per i metadati
Livelli del modello per i metadati¶
Livello 1¶

- Legame dato-metadato:: Nessun legame in quanto i dati non sono accompagnati da un’opportuna metadatazione;
- Livello di dettaglio: Nessuno in quanto i metadati non sono presenti.
Livello 2¶
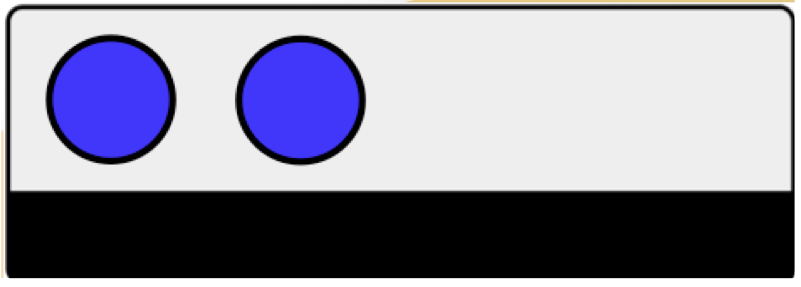
- Legame dato-metadato:: Il legame è debole perché i dati sono accompagnati da metadati esterni, (e.g., inclusi nella pagina di download del dataset o in file separati);
- Livello di dettaglio: I metadati forniscono informazioni relativamente a un dataset, quindi sono informazioni condivise dall’insieme di dati interni a quel dataset.
Livello 3¶
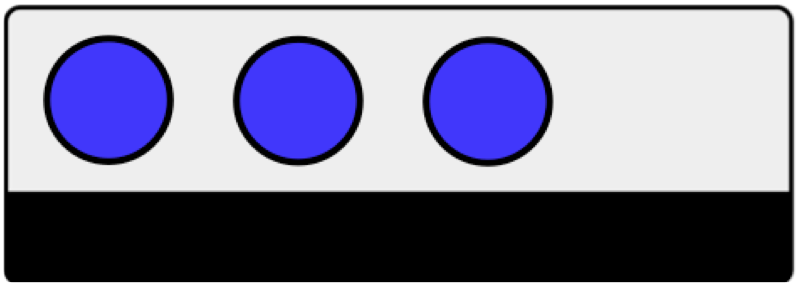
- Legame dato-metadato:: Il legame è forte perché i dati incorporano i metadati che li descrivono;
- Livello di dettaglio: I metadati forniscono informazioni relative a un dataset, quindi sono informazioni condivise dall’insieme di dati interni a quel dataset.
Livello 4¶
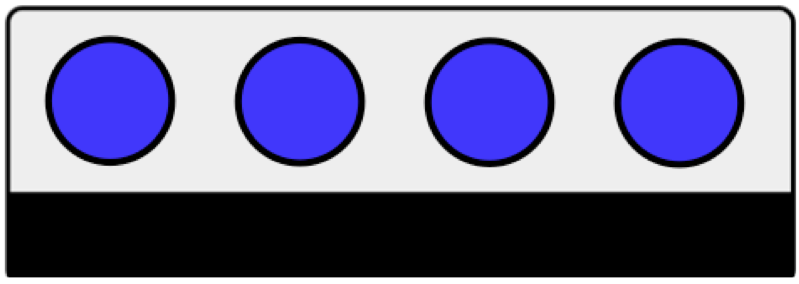
- Legame dato-metadato:: Il legame è forte perché i dati incorporano i metadati che li descrivono;
- Livello di dettaglio: I metadati forniscono informazioni relative al singolo dato, quindi col massimo grado di dettaglio possibile.
Profilo nazionale per i metadati DCAT-AP_IT¶
Nota
AZIONE 5: RISPETTA IL PROFILO DI METADATAZIONE DCAT-AP_IT …
Per i metadati descrittivi generali, ovvero non dipendenti dalle tipologie di dati, si adotta il profilo nazionale DCAT-AP_IT, rispettando le obbligatorietà, le raccomandazioni e seguendo gli esempi così come definiti nella relativa specifica e ontologia. Il profilo, disponibile secondo gli standard del Web Semantico (si veda Architettura dell’informazione del settore pubblico), si basa sullo standard DCAT e su vocabolari ampiamente utilizzati nel Web quali per esempio Dublin Core e schema.org. Il profilo si applica a tutti i tipi di dati pubblici (non solo a dati di tipo aperto), è pienamente conforme a quello europeo DCAT-AP, quest’ultimo nato al fine di uniformare la specifica dei metadati descrittivi per tutti gli stati membri europei, facilitando lo scambio di informazioni e l’interoperabilità anche transfrontaliera e favorendo il riutilizzo e la valorizzazione dell’informazione.
Nel caso di dati geografici, siano essi aperti o non aperti (secondo le definizioni riportate in Dati delle pubbliche amministrazioni), il profilo di metadatazione da adottare è quello del Repertorio Nazionale dei Dati Territoriali (RNDT), conforme alla direttiva INSPIRE, i.e., profilo RNDT/INSPIRE.
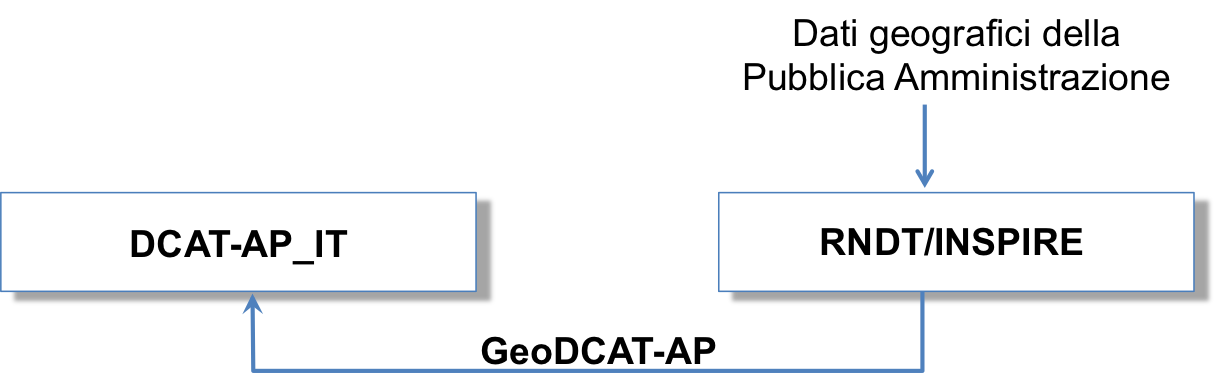
Fig. 4 Figura 4: Relazione tra DCAT-AP_IT e il profilo RNDT/INSPIRE
L’RNDT, in quanto banca dati di interesse nazionale ai sensi dell’articolo 60 del CAD e banca dati critica, è soggetta a regole di interoperabilità e gestione che prevedono, tra le altre, anche l’applicazione del principio “once only”. Secondo questo principio, i dati geografici sono documentati solo una volta e inclusi all’interno del catalogo RNDT, secondo le regole del profilo RNDT/INSPIRE (Figura 4). Sarà lo stesso catalogo, in maniera automatizzata, a fornire l’adeguata integrazione con i metadati descrittivi definiti mediante DCAT-AP_IT, grazie a una specifica estensione per il trattamento dei dati geografici detta GeoDCAT-AP che il Repertorio implementerà a tale scopo.
Lo stesso principio può trovare applicazione anche per altre tipologie di dati, come nel caso dei dati statistici per cui si raccomanda di considerare la relativa estensione StatDCAT-AP, sviluppata in ambito Europeo.
Alcune raccomandazioni per i dataset e le distribuzioni¶
Nell’osservare le pratiche messe in atto dalla amministrazioni per la pubblicazione di dataset e relative distribuzioni, è bene rimarcare in questo documento alcune raccomandazioni sulla metadatazione di questi due elementi.
Nota
Si ricorda che un dataset è una collezione organizzata di dati omogenei generalmente riguardanti una stessa organizzazione.
Si raccomanda, per la classificazione dei dataset e quindi per l’attribuzione dei temi e dei sottotemi, di riferirsi alle «linee guida tecniche per i cataloghi dati» che forniscono sia regole di mappatura rispetto ai temi, sia di mappatura rispetto ai temi e i relativi sotto temi, quest’ultimi modellati mediante la proprietà Dublin Core dct:subject che assume come valori quelli del vocabolario europeo «Eurovoc».
Nel definire il titolo del dataset, si raccomanda di evitare di specificare titoli molto lunghi che appaiono più come descrizioni che come titoli. Il titolo è il nome del dataset che identifica chiaramente il principale contenuto dello stesso.
Sebbene opzionale, si raccomanda, ove possibile, di specificare un titolo per le distribuzioni dei dataset così da facilitare l’utente in fase di navigazione del catalogo dati.
Come gestire le relazioni tra dataset¶
Il vocabolario europeo DCAT tratta la principale entità concettuale dataset come indipendente, vista solo in relazione con il catalogo e le sue distribuzioni. Tuttavia, nella pratica, emergono relazioni più complesse tra dataset, come nel caso delle serie di dati (e.g., serie temporali), dei versionamenti, delle porzioni di un dataset più ampio, o delle collezioni (ovvero dataset che appartengono a un argomento generale ma si basano su diverse dimensioni, sulla base anche di specifici casi d’uso; un esempio è il caso dei dataset sui risultati elettorali). Questa attuale mancanza del vocabolario DCAT si ripercuote anche sul profilo Europeo DCAT-AP che comunque fornisce raccomandazioni per possibili implementazioni in presenza di queste relazioni complesse.
Nota
Nel contesto delle presenti linee guida, si adottano le relative raccomandazioni europee.
In particolare, sebbene si incoraggi le amministrazioni, ove possibile, a limitare la proliferazione di dataset, al fine di modellare le loro inter-relazioni si riportano nel seguito alcuni metodi di rappresentazione:
nel caso di versioning, già l’attuale profilo italiano DCAT-AP_IT prevede l’uso della proprietà Dublin Core *dct:isVersionOf*; le amministrazioni possono anche utilizzare in aggiunta la proprietà inversa dct:hasVersion così da creare una relazione tra due diverse versioni dei dati. Si sconsiglia comunque di creare nuovi dataset per piccoli cambiamenti dei dati. E’ invece consigliato definire nuovi dataset solo in presenza di cambiamenti significativi rispetto a precedenti versioni (e.g., nuovi elementi inclusi, adattamenti significativi di alcuni elementi, ecc);
nel caso di serie di dati, viste sui dataset e collezioni si raccomanda di adottare la seguente soluzione:
Porre enfasi sulla serie, vista o collezione in sé, creando un singolo dataset per la stessa i cui membri sono diverse distribuzioni del dataset creato.
Tuttavia, ove tale soluzione sia di difficile applicazione, è anche possibile porre enfasi sugli elementi individuali della serie, delle viste o delle collezioni. In tal caso si consiglia comunque di procedere nel seguente modo:
- creare un dataset di tipo serie, utilizzando la proprietà Dublin Core dct:type che assume come valore; <http://inspire.ec.europa.eu/metadata-codelist/ResourceType/series>;
- creare per questo dataset tanti membri, a loro volta dataset, specificati mediante la proprietà Dublin Core dct:hasPart;
- i singoli dataset membri della serie avranno una proprietà Dublin Core dct:isPartOf che li lega al dataset iniziale di tipo serie.
Ulteriori metadati di provenienza (Provenance)¶
Le pubbliche amministrazioni possono integrare i metadati previsti dal modello DCAT-AP_IT con metadati aggiuntivi, secondo le proprie necessità seppur nel pieno rispetto delle regole di conformità come definite nella specifica DCAT-AP_IT.
Nota
In particolare, come già riportato in ambito Europeo in DCAT-AP, si raccomanda di inserire metadati sulle entità e sulla filiera di attività, che va dalla generazione alla pubblicazione del dato. Questo consente di certificare in maniera più accurata la reale provenienza del dato e la titolarità dello stesso, fornendo garanzie di qualità per eventuali riutilizzatori.
Per documentare entità e relative attività, lo standard W3C di riferimento da utilizzare è PROV Framework . Attraverso PROV è possibile descrivere in maniera strutturata la provenienza di artefatti e quindi anche di dati che si intende pubblicare, nonché modellare il processo di generazione di un artefatto in maniera quasi analoga ai sistemi di controllo versione.
Il framework PROV è costituito da una famiglia di specifiche articolate in diverse componenti. Per gli scopi delle presenti linee guida, si evidenziano:
- PROV-DM: descrive il modello concettuale dei dati; costituisce quindi il nucleo centrale della famiglia di specifiche. Esso non fa riferimento a uno specifico dominio ma è corredato di estensioni per domini più specifici.
- PROV-O: anche detto PROV Ontology, definisce l’ontologia OWL2 del PROV-DM da utilizzare direttamente nell’ambito del Web Semantico e dei Linked Data. Alla luce di queste caratteristiche, PROV-O si integra perfettamente con il modello di metadatazione nazionale di riferimento DCAT-AP_IT.
- PROV-N: definisce una notazione fruibile da un utente umano per i dati di provenienza creati attraverso il framework.
Metadati di qualità e di struttura del dato¶
Per facilitare ulteriormente i possibili fruitori del dato, e quindi favorire il più ampio riutilizzo dei dati, si raccomanda di considerare anche l’aggiunta di:
- metadati che forniscono una descrizione dello schema del dataset da pubblicare. Nel caso di dati espressi secondo il livello 3 del modello per i dati, lo schema rappresenta l’insieme degli attributi elencati; nel caso dei livelli 4 e 5 esso può essere rappresentato dalle ontologie che accompagnano i dati;
- metadati che forniscono un riscontro della qualità dei dati esposti e di come tale qualità è misurata e certificata. In quest’ultimo caso, si raccomanda di utilizzare le linee guida del W3C pubblicate dal gruppo di lavoro su «Data on the Web Best Practices: Data Quality Vocabulary”.
Avvertimento
Nell’ambito del piano triennale per l’informatica nella PA (2017-2019), è stato individuato un elenco di basi di dati chiave da rendere disponibili secondo il paradigma dei dati aperti. In particolare per queste basi di dati, saranno sviluppate una serie di ontologie/modelli per i dati di riferimento che dovranno essere utilizzati per la definizione della struttura del dato.