10. Allegato: FAQ per la pubblicazione dei dati aperti¶
Le FAQ che seguono sono state elaborate a partire dalle Linee guida per valorizzazione del patrimonio informativo pubblico, a cura dell’Agenzia per l’Italia Digitale e del Dipartimento per la trasformazione digitale della Presidenza del Consiglio dei Ministri [1] (nel seguito anche “Linee guida AgID”). Tali Linee guida hanno l’obiettivo di supportare gli uffici nel processo di valorizzazione del proprio patrimonio informativo pubblico, nel rispetto degli obiettivi indicati nell’articolo 52 del D.lgs 7 marzo 2005, n. 82 - Codice dell’Amministrazione Digitale (CAD).
Le linee guida propongono a tal fine un modello e un’architettura di riferimento per l’informazione del settore pubblico, individuando:
- standard di base, formati, vocabolari/ontologie per dati di specifici domini
- profili di metadati descrittivi nazionali
- aspetti organizzativi necessari per individuare i ruoli e le figure professionali
- fasi dei processi per la gestione e pubblicazione di dati di qualità.
Inoltre, il documento mira a fornire supporto: nella scelta della licenza per i dati di tipo aperto, nell’analisi di eventuali aspetti di costo dei dati e nella loro pubblicazione nei portali per una maggiore standardizzazione di questo processo.
Le linee guida AgID hanno una duplice valenza tecnica e organizzativa e si rivolgono sia a figure professionali delle amministrazioni in possesso di competenze tecnico-informatiche (ad esempio, direttori dei sistemi informativi, responsabili siti web, funzionari e consulenti tecnici), sia a figure professionali individuabili in quelle aree più amministrative preposte all’organizzazione dei dati (ad esempio, responsabili di basi di dati specifiche, responsabili amministrativi, esperti di dominio).
10.1. Cosa sono i dati aperti (open data)?¶
Il Codice dell’Amministrazione digitale (decreto legislativo 7 marzo 2005, n. 82) all’art. 1, definisce aperti i dati:
- disponibili secondo i termini di una licenza o di una previsione normativa che ne permetta l’utilizzo da parte di chiunque, anche per finalità commerciali, in formato disaggregato;
- accessibili attraverso le tecnologie dell’informazione e della comunicazione […] in formati aperti […];
- adatti all’utilizzo automatico da parte di programmi per elaboratori;
- provvisti dei relativi metadati;
- resi disponibili gratuitamente oppure resi disponibili ai costi marginali sostenuti per la loro riproduzione e divulgazione.
Con dato aperto si intende dunque un dato che risponde ai seguenti principi di base:
- Disponibile (requisito giuridico) secondo i termini di una licenza che ne permetta l’utilizzo da parte di chiunque, anche per finalità commerciali, in formato disaggregato;
- Accessibile (requisito tecnologico) attraverso le tecnologie dell’informazione e della comunicazione, in formato aperto e con i relativi metadati;
- Gratuito (requisito economico): disponibili gratuitamente oppure disponibili ai costi marginali sostenuti per la loro riproduzione, messa a disposizione e divulgazione.
I dati aperti del MiC aderiscono ai principi FAIR.
10.2. Cosa sono i principi FAIR?¶
Nel 2014 sono stati elaborati alcuni principi per la condivisione dei dati scientifici, denominati FAIR (acronimo derivante dai termini Findable, Accessible, Interoperable, Re-Usable), per ottimizzare la riutilizzabilità dei dati e dei risultati della ricerca. Tali principi, ormai riconosciuti a livello internazionale, descrivono le caratteristiche che le risorse digitali debbono avere per essere usate e riutilizzate a fini scientifici, educativi e divulgativi, sia dalle persone sia dalle macchine che adottano processi automatizzati.
Rintracciabilità (Findability)
I dati e i relativi metadati raccolti nel progetto devono essere facilmente rintracciabili sia da parte di utenti umani sia da parte di strumenti informatici. Nel DMP va specificato in che modo il progetto soddisfa i requisiti di rintracciabilità, e in particolare tramite:
- Identificatori univoci e persistenti: è opportuno valutare che gli identificatori utilizzati identifichino in maniera univoca le risorse, che non siano soggetti a cambiamento nel tempo, e che i metadati siano collegati in maniera esplicita agli identificatori delle risorse.
- Metadati sufficientemente descrittivi: valutare se i metadati descrivono in modo adeguato le risorse. Inoltre, i metadati devono essere collegati in maniera esplicita agli identificatori univoci.
- Indicizzazione dei metadati: è opportuno verificare che i metadati siano indicizzati in risorse disponibili pubblicamente (es. messe a disposizione dal MiC), in modo che sia semplice reperire le risorse.
Accessibilità (Accessibility)
I dati e i relativi metadati raccolti nel progetto devono essere facilmente accessibili tramite la pubblicazione in repository aperti e disponibili pubblicamente. Nel DMP va specificato in che modo il progetto soddisfa i requisiti di accessibilità, e in particolare tramite:
- Pubblicazione in repository aperti (open access): è opportuno verificare che i dati siano pubblicati in repository aperti, in modo che sia semplice per qualunque utente reperire le risorse, e che sia consentito il riuso dei dati.
- Protocollo di accesso: è opportuno verificare che il dataset venga reso accessibile tramite un protocollo aperto (es. HTTP, FTP).
- Persistenza dei metadati: è opportuno verificare che venga garantita la persistenza dei metadati indipendentemente dall’accessibilità del dataset e indicare se il requisito è soddisfatto.
- Sistemi di autorizzazione e autenticazione: qualora fossero presenti restrizioni sull’accesso ai dati, è opportuno verificare che siano supportati meccanismi di autorizzazione e autenticazione per l’accesso.
Interoperabilità (Interoperability)
I dati e i relativi metadati raccolti nel progetto devono garantire l’interoperabilità, in modo da facilitare il più possibile l’integrazione con altri sistemi e dataset. Nel DMP va specificato in che modo il progetto soddisfa i requisiti di interoperabilità, e in particolare tramite:
- Adozione di standard open data: è opportuno valutare se gli standard e i formati adottati nel progetto garantiscono l’interoperabilità del dataset.
- Adozione di vocabolari compatibili con i principi FAIR:, è opportuno valutare se i vocabolari adottati nel progetto garantiscono l’interoperabilità del dataset.
- Integrazione con altri dataset: è opportuno valutare se è prevista un’integrazione o linking con altri dataset, e con quali modalità.
Riutilizzabilità (Reusability)
I dati e i relativi metadati raccolti nel progetto devono garantire la riutilizzabilità tramite l’adozione di standard, licenze aperte e indicazioni sull’origine dei dati. In questo campo va specificato in che modo il progetto soddisfa i requisiti di riutilizzabilità, e in particolare tramite:
- Adozione di licenze aperte: è opportuno valutare se le licenze adottate rispettano la definizione di licenza aperta (a questo proposito, si vedano le Linee guida per l’acquisizione, la circolazione e il riuso delle riproduzioni dei beni culturali in ambiente digitale).
- Metadati di provenance: è opportuno valutare se i metadati descrivono in maniera adeguata l’origine dei dati e i processi di produzione, raccolta e trasformazione di cui i dati sono stati oggetto.
- Standard per i metadati: è opportuno valutare se le metodologie di metadatazione adottate nel progetto rispettano gli standard di settore.
10.3. Cosa significa formato aperto (#FormatoAperto)?¶
Con formato dei dati di tipo aperto si intende un formato reso pubblico, documentato esaustivamente e neutro rispetto agli strumenti tecnologici necessari per la fruizione dei dati stessi.
Cosa sono i livelli degli open data?
Le Linee guida AgID, che riprendono la definizione di Open Data del W3C [2], prevedono cinque possibili livelli di open data, come di seguito mostrato:
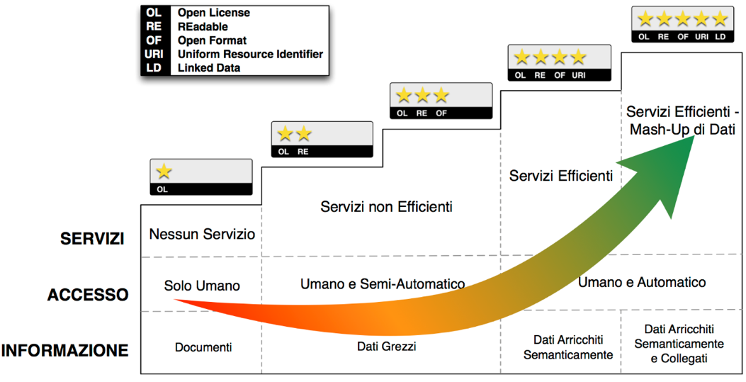
Figura 1 – Livelli di metadatazione
La pubblicazione di dati di livello 1 e 2 non è più consentita; il MiC pertanto pubblicherà i dati in formato aperto almeno di livello 3* mirando, nel tempo, a pubblicare solo dati di livello a 4* e 5* (Linked Open Data).
10.4. Cosa sono i linked (open) data?¶
I linked data (trad.: dati collegati [ad altri dati]) sono una modalità di pubblicazione di dati strutturati basata su tecnologie e standard aperti del web come HTTP, RDF (Resource Description Framework) e URI (Uniform Resource Identifier). Se i linked data collegano dati aperti si parla di linked open data (LOD). I linked data sono una delle tecnologie alla base del cosiddetto Semantic Web (una sorta di spazio globale dei dati interconnessi tra loro con relazioni semanticamente qualificate) in cui i dati, strutturati e collegati tra loro, costruiscono un reticolo informativo sempre più ampio che i software riescono a leggere e interpretare direttamente estraendo informazioni attraverso interrogazioni di tipo semantico. I dati e le relazioni tra essi sono descritti semanticamente tramite metadati e ontologie. Nel collegare (o referenziare) si usano dunque relazioni (“link”) che hanno un preciso significato e spiegano il tipo di legame che intercorre tra le due entità coinvolte nel collegamento. I linked open data sono quindi un metodo elegante ed efficace per risolvere problemi di identità e provenienza, semantica, integrazione e interoperabilità.
Già nel 2012 la Commissione di Coordinamento SPC ha emanato le Linee guida sull’interoperabilità semantica attraverso i linked open data e la metodologia ivi proposta risulta essere ancora valida anche se la filiera di lavorazione dei LOD è un percorso che può essere complesso da intraprendere e che richiede competenze tecniche specifiche. Tuttavia, l’intenzione del MiC è governare una transizione graduale verso la produzione di LOD che sarà possibile se trainata dagli Istituti centrali e dalle Direzioni generali.
10.5. Esistono leggi che impongono di pubblicare dati in formato aperto?¶
Il principio dell’open data by default è stato introdotto nel 2012 con la modifica dell’articolo 52 del Codice dell’Amministrazione Digitale, per cui “i dati e i documenti che [le PA] pubblicano, con qualsiasi modalità, senza l’espressa adozione di una licenza […] si intendono rilasciati come dati di tipo aperto […] ad eccezione dei casi in cui la pubblicazione riguardi dati personali […]”. Altri importanti cambiamenti normativi sono intervenuti soprattutto per quel che riguarda il recepimento della nuova direttiva Europea 2019/1024, che abroga la vigente direttiva 2003/98/CE apportando significative novità in tema di riutilizzo dei dati aperti della PA: essa accresce la rilevanza economica del riutilizzo degli open data andando ad estenderne il campo di applicazione alle attività di interesse economico generale, ai “dati dinamici” e “di elevato valore” nonché ai dati prodotti nell’ambito della ricerca scientifica.
La direttiva 2019/1024 sul riuso dei dati prodotti dalla pubblica amministrazione (Public Sector Information) è la terza direttiva PSI in ordine di tempo: la direttiva PSI del 2013, rispetto alla prima del 2003, ha incluso per la prima volta nel proprio ambito di applicazione i dati detenuti musei, archivi e biblioteche, ma ha finito per rimanere in buona parte priva di effetti su questi istituti per la mancata emanazione del decreto ministeriale, che avrebbe dovuto definire i criteri di tariffazione legati al riuso dei dati detenuti dagli istituti pubblici di tutela.
10.6. Tutti i dati devono essere pubblicati in formato aperto?¶
Tutti i dati detenuti dalle pubbliche amministrazioni devono essere pubblicati in formato aperto, con le seguenti esclusioni:
- dati a conoscibilità limitata come i dati coperti da segreto di stato o le opere d’ingegno coperte dal diritto d’autore;
- i dati personali, per i quali trovano applicazione le norme del «Codice in materia di protezione dei dati personali» (i.e., D.lgs n. 196/2003 e Linee guida in materia di trattamento di dati personali e s.m.i.). In questo caso, si ponga anche attenzione a non esporre quasi-identificatori (e.g., data di nascita, domicilio, residenza, sesso, etnia, composizione nucleo famigliare, status giuridico, ecc.) che possono facilmente re-identificare i soggetti che si intende invece tutelare o che hanno una tutela speciale perché appartenenti a fasce protette (e.g., testimoni giudiziari, profughi, rifugiati, pentiti, ecc.). In ogni caso, AgiD raccomanda di verificare gli artt. 3 e 4 del D. Lgs. 36/2006 per una visione approfondita circa le esclusioni e le norme di salvaguardia.
Per quanto riguarda le riproduzioni digitali dei beni culturali, un limite alla pubblicazione in formato aperto è rappresentato dalle prescrizioni dell’art. 107 e 108 del Codice dei beni culturali, dove si prevede la corresponsione di un canone per i riusi commerciali; nessuna limitazione è invece posta dal Codice alla pubblicazione in formato aperto dei dati descrittivi del patrimonio culturale. Per un approfondimento sul tema si rimanda alle Linee guida per l’acquisizione, la circolazione e il riuso delle riproduzioni di beni culturali in ambiente digitale.
AgID fornisce una breve “check list”, utile per verificare se tutti gli aspetti giuridici sono stati valutati dal responsabile della banca dati. La check list è formata da una serie di domande, per ciascun aspetto, a cui rispondere con Sì o No.
| AMBITO | DOMANDA DI CONTROLLO | SI/NO |
|---|---|---|
| Privacy | I dati sono liberi da ogni informazione personale che possa identificare in modo diretto l’individuo (nome, cognome, indirizzo, codice fiscale, patente, telefono, email, foto, descrizione fisica, ecc.)? In caso negativo queste informazioni sono autorizzate per legge? | |
| I dati sono liberi da ogni informazione indiretta che possa identificare l’individuo (caratteristiche personali che possono identificare facilmente il soggetto)? In caso negativo queste informazioni sono autorizzate per legge? | ||
| I dati sono liberi da ogni informazione sensibile riconducibile all’individuo? In caso negativo queste informazioni sono autorizzate per legge? | ||
| I dati sono liberi da ogni informazione relativa al soggetto che incrociata con dati comunemente reperibili nel web (e.g. google maps,linked data, ecc.) possa identificare l’individuo? In caso negativo queste informazioni sono autorizzate per legge? | ||
| I dati sono liberi da ogni riferimento a profughi, protetti di giustizia, vittime di violenze o in ogni caso categorie protette? | ||
| Hai considerato il rischio di de-anonimizzazione del tuo dataset prima di pubblicarlo? | ||
| Esponi dei servizi di ricerca tali da poter filtrare i dati in modo da ottenere un solo record geolocalizzato, che sia facilmente riconducibile ad una persona fisica? |
| Proprietà intellettuale della sorgente | Il dataset è stato creato da uno o più dipendenti della tua pubblica amministrazione nell’ambito della loro attività lavorativa? I singoli elementi del dataset suscettibili di autonoma protezione (es., immagini, fotografie, testi in qualche modo creativi) sono stati a loro volta prodotti da uno o più dipendenti della tua pubblica amministrazione nell’ambito della loro attività lavorativa? | |
| L’amministrazione è proprietaria dei dati, anche se non sono stati creati direttamente da suoi dipendenti?? | ||
| Sei sicuro di non usare dati per i quali vi è una licenza o un brevetto di terzi? | ||
| Se i dati non sono della tua amministrazione hai un accordo o una licenza che ti autorizzi a pubblicarli? | ||
| Licenza di rilascio | Stai rilasciando i dati di cui possiedi la proprietà accompagnati da una licenza? | |
| Hai incluso anche la clausola di salvaguardia «Questo dataset contiene informazioni indirettamente riferibili a persone fisiche. In ogni caso, i dati non possono essere utilizzati al fine di identificare nuovamente gli interessati.»? | ||
| Limiti alla pubblicazione | Hai verificato che non vi siano impedimenti di legge o contrattuali che per la pubblicazione dei dati? | |
| Segretezza | Hai verificato se non vi siano motivi di ordine pubblico o di sicurezza nazionale che ti impediscono la pubblicazione dei dati? | |
| Hai verificato se non vi siano motivi legati al segreto d’ufficio che impediscono la pubblicazione dei dati? | ||
| Hai verificato se non vi siano motivi legati al segreto di stato che impediscono la pubblicazione dei dati? | ||
| Indicazioni temporali | I dati sono soggetti per legge a restrizioni temporali di pubblicazione? | |
| I dati sono aggiornati frequentemente in modo da sanare eventuali informazioni lesive di persone o organizzazioni? | ||
| I dati hanno dei divieti di legge o giurisprudenziali che impediscono la loro indicizzazione da parte di motori di ricerca? | ||
| Trasparenza | I dati rientrano nella lista dell’allegato A del d.lgs. 33/2013? Se sì come sono stati trattati dal responsabile della trasparenza nella sezione “Amministrazione trasparente”? |
10.7. E se i dati contengono riferimenti espliciti a persone (dato personale)?¶
In questo caso i dati non vanno pubblicati in formato aperto, a meno che non sia possibile procedere all’anonimizzazione del dato. I dati possono essere considerati anonimi quando le persone non sono più identificabili. Infatti, esistono molte altre informazioni che consentono a un individuo di essere collegato ai suoi dati personali e che ne consentono pertanto la reidentificazione. Il GDPR, però, non prescrive alcuna tecnica particolare per l’anonimizzazione; spetta quindi ai singoli responsabili del trattamento garantire che qualunque processo di anonimizzazione scelto sia sufficientemente solido.
10.8. Che vantaggi si traggono dalla pubblicazione dei dati aperti?¶
La valorizzazione del patrimonio informativo pubblico è un obiettivo strategico per la pubblica amministrazione, soprattutto per affrontare efficacemente le nuove sfide dell’economia dei dati (data economy), supportare la costruzione del mercato unico europeo per i dati definito dalla Strategia europea in materia di dati [3], garantire la creazione di servizi digitali a valore aggiunto per cittadini, imprese e, in generale, tutti i portatori di interesse e fornire al decisore politico strumenti data-driven da utilizzare nei processi decisionali.
A tal fine, il Piano triennale per l’informatica nella Pubblica Amministrazione ridefinisce una nuova data governance coerente con la Strategia europea e con il quadro delineato dalla nuova Direttiva europea sull’apertura dei dati e il riutilizzo dell’informazione del settore pubblico.
Il principio generale della direttiva è quello di favorire al massimo il riutilizzo dei dati della pubblica amministrazione, a eccezione dei dati esclusi dal diritto di accesso ai sensi del diritto nazionale e in conformità alla normativa sulla protezione dei dati. Questo principio muove dalla convinzione che il libero riutilizzo dei dati, anche per fini commerciali, è un potente moltiplicatore di ricchezza e un asset strategico per lo sviluppo sociale, culturale ed economico dei Paesi membri in una fase di forte crescita dei settori che si occupano dell’elaborazione di dati grezzi in materiale per lo sviluppo di nuove app e servizi che possono essere erogati da soggetti pubblici e privati: maggiore è infatti la qualità e quantità degli Open Data messi a disposizione dalle pubbliche amministrazioni, e maggiori saranno le probabilità che i dati verranno utilizzati al fine di creare servizi innovativi capaci di divenire fattori di benessere per la società.
Per tali ragioni già la direttiva del 2013 prescriveva l’obbligo, e non più solamente la facoltà, per le amministrazioni, di rendere riutilizzabili per fini commerciali o non commerciali i dati in loro possesso, ove possibile per via elettronica e in formati aperti, leggibili meccanicamente, accessibili, reperibili e riutilizzabili, insieme ai rispettivi metadati.
10.9. Si possono fare pagare i dati?¶
La condivisione dei dati tra pubbliche amministrazioni per finalità istituzionali (art. 50 del CAD), avviene esclusivamente a titolo gratuito. Anche nel caso della pubblicazione di open data, AgID suggerisce di renderli disponibili esclusivamente a titolo gratuito. Tuttavia, è prevista la possibilità di richiedere per il riutilizzo dei dati un corrispettivo specifico, limitato ai costi sostenuti effettivamente per la riproduzione, messa a disposizione e divulgazione dei dati. In tali casi, come previsto dall’art. 7 del D.Lgs 24 gennaio 2006, n. 36, AgID determina le tariffe standard da applicare, pubblicandole sul proprio sito istituzionale. Nel pieno rispetto dei principi di trasparenza e verificabilità, tali tariffe sono determinate sulla base del “Metodo dei costi marginali” esplicitato nella Comunicazione della Commissione 2014/C - 240/01 contenente, tra gli altri, gli orientamenti sulla tariffazione. In linea con quanto previsto dalla direttiva comunitaria, il citato articolo 7 del D. Lgs. 36/2006 prevede inoltre casi specifici per i quali è possibile determinare tariffe superiori ai costi marginali in deroga al principio generale di rendere disponibili i dati gratuitamente o a costi marginali, ovvero:
- alle biblioteche, comprese quelle universitarie, di musei e archivi;
- alle amministrazioni e agli organismi di diritto pubblico che devono generare utili per coprire una parte sostanziale dei costi inerenti allo svolgimento dei propri compiti di servizio pubblico;
- ai casi eccezionali relativi a documenti per i quali le pubbliche amministrazioni e gli organismi di diritto pubblico sono tenuti a generare utili sufficienti per coprire una parte sostanziale dei costi di raccolta, produzione, riproduzione e diffusione.
Alla data di elaborazione del presente documento sono in corso di redazione da parte di AgID i criteri per la determinazione di tali tariffe.
Per quanto riguarda invece i criteri per la tariffazione delle riproduzioni dei beni culturali, si rimanda a quanto previsto nelle Linee guida per l’acquisizione, la circolazione e il riuso delle riproduzioni digitali dei beni culturali in ambiente digitale.
10.10. Con che licenza si devono pubblicare i dati aperti (#Licenza)?¶
Per licenza d’uso si intende il contratto, o altro strumento negoziale, redatto ove possibile in forma elettronica, nel quale sono definite le modalità di riutilizzo dei documenti delle pubbliche amministrazioni o degli organismi di diritto pubblico.
L’informazione sul tipo di licenza è un metadato indispensabile per determinare come poter riutilizzare il dataset (ovvero l’insieme organico dei dati resi disponibili). Deve pertanto essere sempre specificata indicando, il nome, la versione e fornendo il riferimento al testo della licenza.
Nel contesto dei dati aperti, considerando la definizione Open Data fornita dal CAD e dall’Open Knowledge Foundation (OKFN), per cui un dato è aperto se è “liberamente usabile, riutilizzabile e ridistribuibile da chiunque per qualsiasi scopo, soggetto al massimo alla richiesta di attribuzione e condivisione allo stesso modo”, non tutte le licenze d’uso sono compatibili con i principi dei dati aperti. Nella figura che segue le licenze vengono classificate secondo tale criterio:
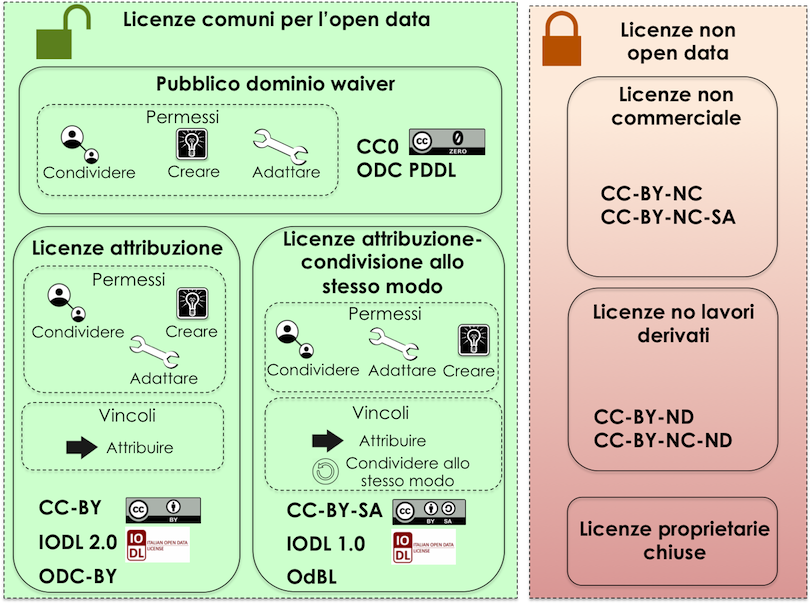
Figura 5 - Lo schema è tratto dalla figura disponibile al seguente link: https://docs.italia.it/italia/daf/lg-patrimonio-pubblico/it/stabile/licenzecosti.html#id5
Tutte le licenze che non consentono lavori derivati, anche per finalità commerciali, i.e., licenze che riportano chiaramente clausole Non Commercial - NC e/o Non Derivative – ND e/o ogni altra clausola che limita la possibilità di riutilizzo e ridistribuzione dei dati, non possono essere ritenute valide per identificare dataset aperti.
Le licenze più usate per gli open data appartengono a tre categorie principali:
- il pubblico dominio o “waiver” dove il dichiarante “apertamente, pienamente, permanentemente, irrevocabilmente e incondizionatamente rinuncia, abbandona e cede ogni proprio diritto d’autore e connesso, ogni relativa pretesa, rivendicazione, causa e azione, sia al momento nota o ignota (includendo espressamente le pretese presenti come quelle future) relativa all’opera”. Rientrano in questa categoria la CC0 della famiglia delle licenze internazionali Creative Commons e la Open Data Commons – Public Domain Dedication License (ODC-PDDL) per i dataset/database;
- le licenze per l’open data con richiesta di attribuzione, che consentono di condividere, adattare e creare anche per finalità commerciali con il solo vincolo di attribuire la paternità del dataset. Rientrano in questa categoria la licenza CC-BY della famiglia Creative Commons, la IODL (Italian Open Data License) nella sua versione 2.0 e la Open Data Commons Attribution License (ODC-BY) per dataset/database.
- le licenze per l’open data con richiesta di attribuzione e condivisione allo stesso modo, che consentono di condividere, adattare e creare anche per finalità commerciali nel rispetto però di due vincoli: a) attribuire la paternità del dataset; b) distribuire eventuali lavori derivati con la stessa licenza che governa il lavoro originale. Rientrano in questa categoria la licenza CC-BY-SA della famiglia Creative Commons la IODL nella sua versione 1.0 la Open Data Commons Open Database License (ODbL) utilizzata dal progetto OpenStreetMap (OSM).
In relazione a quanto sopra riportato, tenuto conto del contesto normativo di riferimento, si ritiene opportuno fare riferimento ad una licenza unica aperta per tutto il MiC, che garantisca libertà di riutilizzo, che sia internazionalmente riconosciuta e che consenta di attribuire la paternità dei dataset (attribuire la fonte). Pertanto, si suggerisce l’adozione generalizzata della licenza CC-BY nella sua versione 4.0, presupponendo altresì l’attribuzione automatica di tale licenza nel caso di applicazione del principio “Open Data by default”, espresso nelle disposizioni contenute nell’articolo 52 del CAD. Per le immagini dei beni culturali, si rimanda a quanto previsto nelle Linee guida per l’acquisizione, la circolazione e il riuso delle riproduzioni di beni culturali in ambiente digitale.
Per finalità particolari, ad esempio per il conferimento dei dati a portali di valorizzazione del patrimonio culturale (cfr. Europeana) o progetti collaborativi di divulgazione del sapere (cfr. Wikidata), se richiesto dall’adesione al portale o al progetto, il MiC può valutare l’opportunità di rilasciare alcuni dataset con le licenze richieste dai suddetti progetti e portali.
AgiD raccomanda inoltre di gestire l’attribuzione della fonte indicando il nome dell’organizzazione unitamente all’URL della pagina Web dove si trovano i dataset/contenuti da licenziare. Nell’applicazione della licenza si ricorda che non si può disporre/attribuire diritti più ampi rispetto alla licenza di partenza (e.g., non si può attribuire un pubblico dominio - o waiver - a un dataset ottenuto da una fonte a cui è associata una licenza che richiede attribuzione).
Infine, le amministrazioni possono prevedere casi di applicazione di licenze che limitino il riutilizzo dei dati se e solo se ciò si renda necessario per il rispetto di altre normative (e.g., norme in materia di protezione dei dati personali) e comunque motivando opportunamente la scelta.
A completamento dell’argomento, si evidenzia l’opportunità di verificare gli aspetti relativi a:
- titolarità dei dati secondo la competenza amministrativa
- elaborazione di un’opera derivata, con il conseguente onere di citazione della fonte originale del dataset e di specifica attribuzione all’opera derivata
- finalità per i quali i dati sono stati creati che eventualmente non consentono di renderli automaticamente disponibili in open data
- responsabilità del titolare rispetto al riutilizzo dei dati da parte di terzi e, nel caso, specificare una nota legale, che integra e accompagna la licenza.
Un’indicazione di compatibilità tra le licenze Open Data è riportata nella tabella seguente:
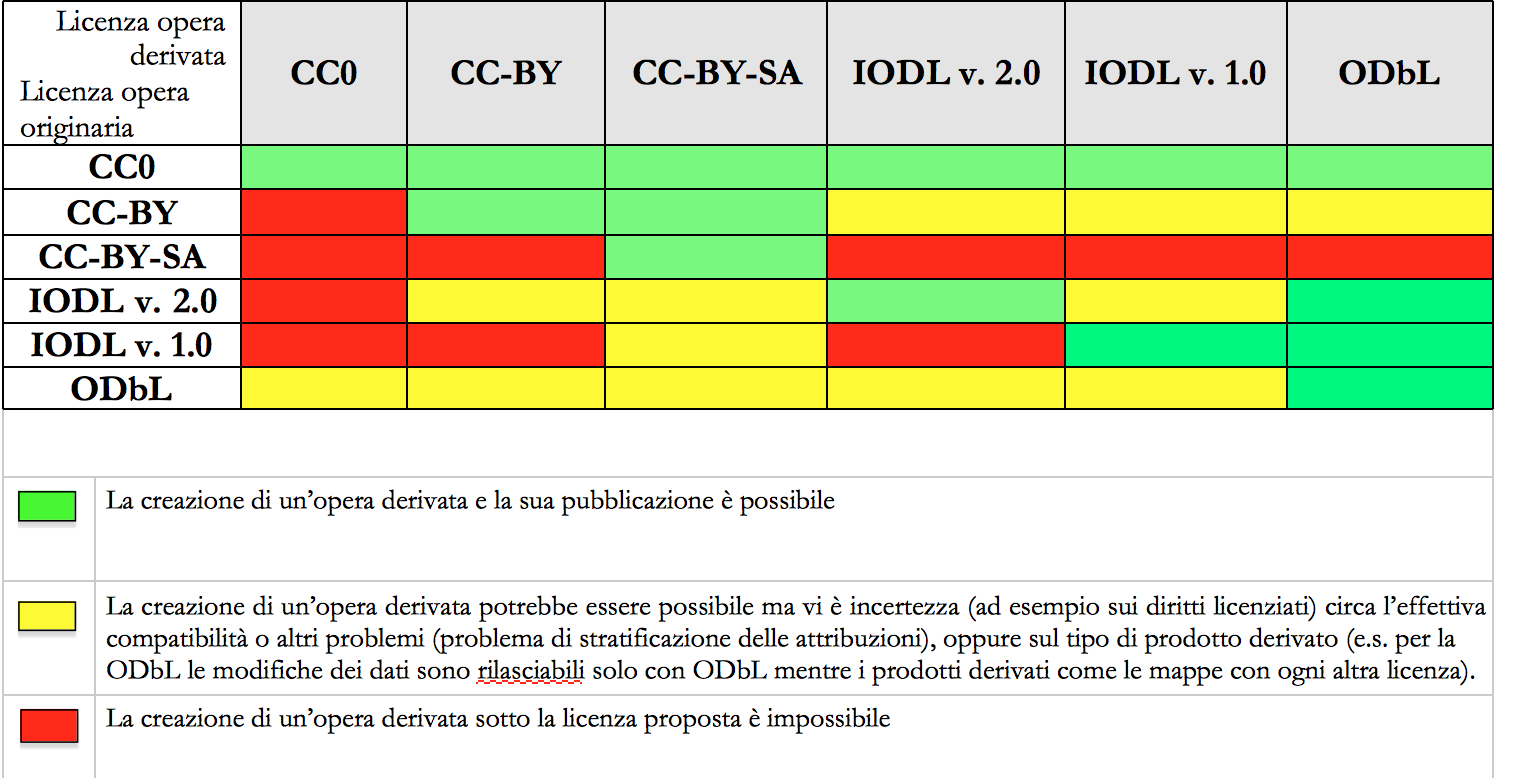
10.11. Cosa sono le licenze Creative Commons (CC)¶
Le licenze più note a livello internazionale sono le Creative Commons (CC) [4], proposte nel 2002 da Lawrence Lessig, d’uso ormai sempre più comune nell’editoria, nel mercato audiovisivo e nelle pratiche di digitalizzazione delle collezioni museali in tutto il mondo; tali licenze favoriscono una gestione più flessibile e intuitiva dei diritti d’autore gravanti sulle opere rilasciate in rete mediante il ricorso a loghi internazionalmente riconosciuti e a metadati machine-readable in grado di rendere immediatamente comprensibili all’utenza i termini di utilizzo dell’opera. Lo strumento della licenza ha dunque il pregio di permettere all’autore dell’opera, o comunque al titolare dei diritti di sfruttamento economici, una gestione più agile ed equilibrata dei propri diritti favorendo al tempo stesso un uso più responsabile e consapevole delle risorse digitali da parte del pubblico. Le licenze CC si basano sul concetto di “some rights reserved” (alcuni diritti riservati) in opposizione alla formula tradizionale “all rights reserved” (tutti i diritti riservati).
Le licenze CC sono complessivamente sei e derivano dalla combinazione dei seguenti quattro attributi:
- Attribuzione/Attribution (BY): l’utente è tenuto ad attribuire la paternità dell’opera nel modo indicato dall’autore stesso;
- Non opere derivate/No Derivatives (ND): l’opera non può essere alterata o modificata dall’utente in nessun modo, né utilizzata per crearne una simile. È alternativa alla SA;
- Non commerciale/Non Commercial (NC): l’opera non può essere sfruttata dall’utente per fini commerciali;
- Condividi allo stesso modo/Share Alike (SA): l’opera può essere modificata e può circolare solo per il tramite di una licenza equivalente a quella originaria. È alternativa alla ND.
Oltre alle sei licenze autoriali Creative Commons mette a disposizione altri due strumenti specificatamente riservati alle opere in pubblico dominio: l’etichetta PDM (Public Domain Mark) e il dispositivo CC0. PDM è propriamente un’etichetta, non una licenza, concepita per comunicare che l’opera risulta priva di restrizioni sul piano del diritto d’autore note a livello internazionale. Il dispositivo CC0 è invece uno strumento, dotato di valore legale (a differenza di PDM), che permette all’autore di rinunciare a ogni diritto sulle opere prodotte, compreso quello di attribuzione espressa (BY). In questo modo l’opera entra nel pubblico dominio non già in seguito alla scadenza dei termini di protezione, bensì per scelta volontaria del suo autore.
10.12. Come definire una lista di priorità per pubblicare i dati in formato aperto?¶
La strategia nazionale per gli open data delineata a partire dal 2017 nel “Piano Triennale per l’informatica nella PA” suggerisce un percorso che passa attraverso varie fasi operative:
- individuazione di basi di dati altamente affidabili ed essenziali per un elevato numero di procedimenti amministrativi (altrimenti dette basi di dati di interesse nazionale o base register secondo la terminologia prevista nell’ambito dell’European Interoperability Framework),
- apertura, in open data, della gran parte dei dati prodotti dalle amministrazioni, nel rispetto degli ambiti di applicazione previsti dalle norme,
- definizione di vocabolari controllati e modelli dati, da rendere disponibili in un apposito registro consultabile da chiunque,
- messa a disposizione di uno spazio dei dati che offre, tra gli altri, un servizio di Open Data as a Service (ODasS) certificati.
Nel contesto dei dati aperti, la strategia complessiva a livello nazionale include inoltre la definizione di un “Paniere dinamico di dataset” (inserito nel piano triennale e aggiornabile di anno in anno) attraverso il quale è individuato un insieme di basi di dati, sia regionali, sia nazionali, che le amministrazioni intendono rendere disponibili in open data. All’interno del paniere si considerano altresì richieste specifiche di dati da aprire provenienti da iniziative ufficiali con la cittadinanza (e.g., Open Government Partnership Forum).
Tali elementi costituiscono anche la base di riferimento per diverse azioni di monitoraggio che devono essere intraprese per dar seguito sia agli impegni assunti nell’ambito del piano triennale, sia alle disposizioni dell’articolo 52 del Codice dell’Amministrazione Digitale e della suddetta Direttiva PSI 2.0. Il MiC segnala annualmente ad AgID quali basi di dati nazionali metterà a disposizione in linked open data, tra quelle detenute dagli Istituti centrali e dalle Direzioni generali.
10.13. Cosa sono le ontologie e a cosa servono?¶
In informatica, un’ontologia è una rappresentazione formale, condivisa ed esplicita di una concettualizzazione di un dominio di interesse. Il termine ontologia formale è entrato in uso nel campo dell’intelligenza artificiale e della rappresentazione della conoscenza, per descrivere il modo in cui diversi schemi vengono combinati in una struttura dati contenente tutte le entità rilevanti e le loro relazioni in un dominio. I software usano le ontologie per vari scopi, tra cui il ragionamento induttivo, la classificazione, etc.
AgID raccomanda di modellare i dati sulla base dei vocabolari e ontologie di OntoPiA in larga parte allineati (collegati) a standard aperti del Web e disponibili in formati aperti standard sulla piattaforma https://github.com/italia/.
Gli uffici del MiC, per il tramite degli Istituti centrali, sono incoraggiati ad avviare un processo di standardizzazione sia per la rappresentazione di dati ricorrenti, indipendenti dallo specifico dominio applicativo, come per esempio i dati sulle persone, sulle organizzazioni pubbliche e private, sui luoghi e gli indirizzi usando le ontologie di OntoPiA [5] sia per la rappresentazione di dati più settoriali relativi a specifiche banche dati o a specifici procedimenti o per i dati pubblicati nella sezione «Amministrazione Trasparente».
È fondamentale, quindi, nella scelta delle ontologie da utilizzare, nell’ordine:
- avvalersi di ontologie della rete OntopiA
- usare ontologie rilasciate come standard dal W3C
- usare ontologie pubblicate e aggiornate da grandi Istituzioni (es Library on Congress, ICOM, Europeana)
- usare altre ontologie che siano pubblicate su siti istituzionali, ben documentate e, preferibilmente, e la documentazione disponibile almeno due lingue.
L’utilizzo di una rete di ontologie standard può facilitare la creazione di collegamenti tra dati, portando alla costruzione di una grande base di conoscenza dell’informazione del settore culturale da utilizzare per lo sviluppo di servizi nuovi e proattivi. Per una visione complessiva dell’architettura dell’informazione pensata per il settore pubblico si rimanda allo schema descritto da AgID all’indirizzo:
https://docs.italia.it/italia/daf/lg-patrimonio-pubblico/it/stabile/arch.html#id1.
10.14. Quali sono gli standard di riferimento per il settore pubblico?¶
I principali standard di riferimento per l’architettura dell’informazione del settore pubblico derivano dalle esperienze maturate dagli esperti nel settore del Web Semantico, con la visione di trasformare il Web in un unico spazio informativo globale. Essi sono:
- RDF (Resource Description Framework)
- RDFS (RDF Schema)
- OWL (Web Ontology Language)
- SPARQL (SPARQL Protocol and RDF Query Language)
- SDMX (Statistical Data and Metadata eXchange)
Tali standard sono ampiamente documentati sul web e descritti anche nelle Linee guida AgID [6].
10.15. Cos’è il portale dati.gov.it?¶
Ai sensi dell’articolo 1 comma 8 del D.Lgs. 18 maggio 2015, n.102, il portale nazionale dei dati aperti (dati.gov.it) è l’unico riferimento per la documentazione e la ricerca di tutti i dati aperti della pubblica amministrazione. Esso, inoltre, è l’unico ad abilitare il colloquio con l’analogo portale europeo. Il portale nazionale dei dati aperti include i metadati, conformi al profilo DCAT-AP_IT, che descrivono i dati aperti delle amministrazioni. Le amministrazioni sono tenute, pertanto, a inserire e a mantenere aggiornati, attraverso le modalità di alimentazione previste dal catalogo, tali metadati. I dati primari, il cui riferimento è pubblicato sul portale nazionale, rimangono presso il titolare del dato che conserva la responsabilità della loro divulgazione a livello nazionale. I dati geografici devono essere documentati esclusivamente presso il Repertorio Nazionale dei Dati Territoriali (RNDT) che, in maniera automatizzata, si occupa dell’allineamento con il portale nazionale dei dati.
Il MiC assicura il conferimento dei propri dati aperti a dati.gov.it attraverso il proprio Catalogo dei dati pubblicato sul sito https://dati.cultura.gov.it.
Il portale dati.gov.it predispone i metadati per l’harvesting da parte del portale europeo e prevede una funzionalità di harvesting periodica (con frequenza settimanale) e automatizzata verso i cataloghi dei dati aperti delle altre amministrazioni.
Al fine di evitare duplicazioni di dati e di ridurre la complessità della raccolta centrale di informazioni sui dataset presenti nei cataloghi delle amministrazioni, si adotta un modello di governance del processo di alimentazione del catalogo nazionale dati.gov.it. Il modello di governance prevede di avvalersi dei principi di sussidiarietà verticale, già in precedenza menzionati. I meccanismi di alimentazione del portale nazionale abilitano, di fatto, una federazione tra portali di pubbliche amministrazioni 7.
10.16. Cos’è il portale dati.cultura.gov.it?¶
Il sito https://dati.cultura.gov.it è il portale dove sono pubblicati i dati aperti del Ministero della cultura, la cui manutenzione è stata affidata dalla DG Organizzazione all’Istituto Centrale per il Catalogo e la Documentazione. Dal portale è possibile interrogare l’endpoint SPARQL dove sono accessibili i linked open data (LOD) prodotti dal MiC. I primi LOD sono stati pubblicati a partire dal 2014 rappresentano il frutto di un processo di cooperazione tra gli Istituti centrali e le Direzioni generali del MiC e collegano tra loro dataset provenienti da fonti diverse: banca dati dei Luoghi della cultura; anagrafiche di Archivi e Biblioteche; banca dati del Catalogo dei beni culturali; altre banche dati documentali e fotografiche. Allo stato attuale la piattaforma è essenzialmente un’interfaccia sperimentale machine-to-machine (m2m) che offre linked open data interrogabili via endpoint SPARQL.
| [1] | Cfr. https://docs.italia.it/italia/daf/lg-patrimonio-pubblico/it/stabile/index.html. |
| [2] | Cfr. https://dvcs.w3.org/hg/gld/raw-file/default/glossary/index.html#x5-star-linked-open-data |
| [3] | Cfr. https://ec.europa.eu/info/strategy/priorities-2019-2024/europe-fit-digital-age/european-data-strategy_it |
| [4] | Cfr. https://creativecommons.it/chapterIT/ |
| [5] | In particolare il MiC collabora ad OntoPiA con le ontologie: 1)Cultural-ON per la modellazione dei dati relativi agli Istituti della Cultura e agli eventi culturali; 2) ArCo, rete di ontologie per la modellazione dei beni culturali afferenti ai beni archeologici, architettonico-paesaggistici, demoetnoantropologici, fotografici, naturalistici, numismatici, scientifico-tecnologici, storico-artistici, strumenti musicali. |
| [6] | https://docs.italia.it/italia/daf/lg-patrimonio-pubblico/it/stabile/arch.html#standard-di-riferimento |